前言
Linux本文介绍了几种实用的Linux系统资源监控工具,主要用于监控CPU、内存、磁盘、和网卡……
资源及对应监控工具
本文章使用的命令均可以通过man a tool来查看详细说明……
CPU
top
top输出
top命令如下:
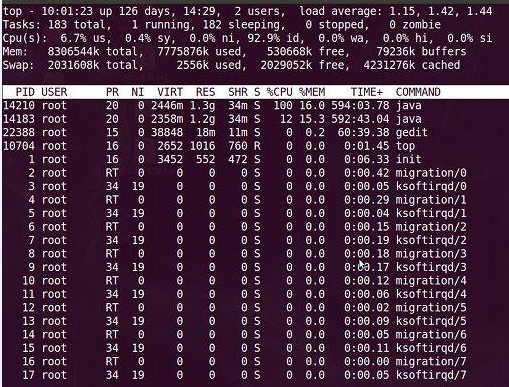
下面详细讲解top命令各参数含义:
- 第一行(CPU负载)
10:01:23 — 当前系统时间
126 days, 14:29 — 系统已经运行了126天14小时29分钟(在这期间没有重启过)
2 users — 当前有2个用户登录系统(用w命令验证)
load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况(load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了)
- 第二行(进程状态)
Tasks — 任务(进程),系统现在共有183个进程,其中处于运行中的有1个,182个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸进程)的有0个
- 第三行(CPU使用比例)
6.7% us — 用户空间占用CPU的百分比
0.4% sy — 内核空间占用CPU的百分比
0.0% ni — 改变过优先级的进程占用CPU的百分比
92.9% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.0% si — 软中断(Software Interrupts)占用CPU的百分比
- 第四行(内存使用)
8306544k total — 物理内存总量(8.3GB)
7775876k used — 使用中的内存总量(7.7GB)
530668k free — 空闲内存总量(530M)
79236k buffers — OS缓存的内存量 (79M)
- 第五行(swap交换分区)
2031608k total — 交换区总量(2GB)
2556k used — 使用的交换区总量(2.5M)
2029052k free — 空闲交换区总量(2GB)
4231276k cached — OS cache的内存量(4GB)
- 第七行以下:各进程(任务)的状态监控
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
top视图
- top视图1(多U多核CPU监控)
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
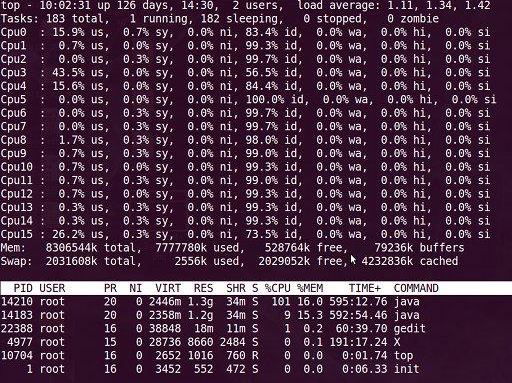
观察上图,服务器有16个逻辑CPU,实际上是4个物理CPU
- top视图2(打开/关闭加亮效果)
敲击键盘“b”(打开/关闭加亮效果),top的视图变化如下:
- top视图3(运行态进程加亮显示)
可以通过敲击“y”键关闭或打开运行态进程的加亮效果:
我们发现进程id为10704的“top”进程被加亮了,top进程就是视图第二行显示的唯一的运行态(runing)的那个进程
- top视图4(排序列的加亮显示)
敲击键盘“x”(打开/关闭排序列的加亮效果),top的视图变化如下:
可以看到,top默认的排序列是“%CPU”
- top视图5(向右或左改变排序列)
通过”shift + >”或”shift + <”可以向右或左改变排序列,下图是按一次”shift + >”的效果图:
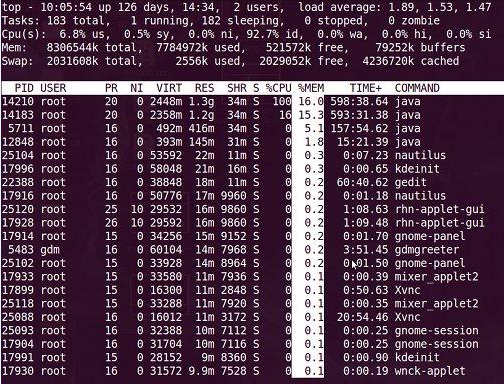
视图现在已经按照%MEM来排序了
- top视图6(改变进程显示字段)
敲击“f”键,top进入另一个视图,在这里可以编排基本视图中的显示字段:
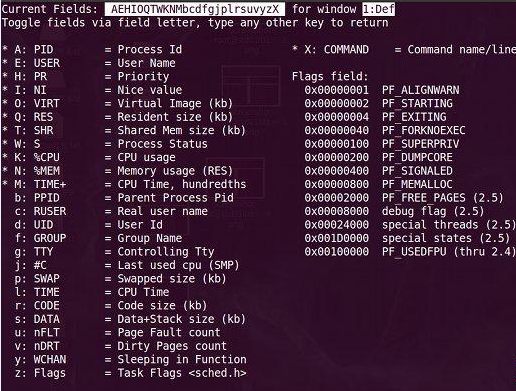
这里列出了所有可在top基本视图中显示的进程字段,有*并且标注为大写字母的字段是可显示的,没有*并且是小写字母的字段是不显示的。如果要在基本视图中显示“CODE”和“DATA”两个字段,可以通过敲击“r”和“s”键:
top命令补充
1、top命令是Linux上进行系统监控的首选命令,但有时候却达不到我们的要求,比如当前这台服务器,top监控有很大的局限性。这台服务器运行着websphere集群,有两个节点服务,就是【top视图 01】中的老大、老二两个java进程,top命令的监控最小单位是进程,所以看不到我关心的java线程数和客户连接数,而这两个指标是java的web服务非常重要的指标,通常我用ps和netstate两个命令来补充top的不足
- 监控java线程数:
ps -eLf | grep java | wc -l
- 监控网络客户连接数:
netstat -n | grep tcp | grep port | wc -l
上面两个命令,可改动grep的参数,来达到更细致的监控要求
2、在Linux系统“一切都是文件”的思想贯彻指导下,所有进程的运行状态都可以用文件来获取。系统根目录/proc中,每一个数字子目录的名字都是运行中的进程的PID,进入任一个进程目录,可通过其中文件或目录来观察进程的各项运行指标,例如task目录就是用来描述进程中线程的,因此也可以通过下面的方法获取某进程中运行中的线程数量(PID指的是进程ID):
ls /proc/PID/task | wc -l
3、在linux中还有一个命令pmap,来输出进程内存的状况,可以用来分析线程堆栈:
pmap PID
Memory
free
free输出
解释一下Linux上free命令的输出
下面是free的运行结果,一共有4行。为了方便说明,我加上了列号。这样可以把free的输出看成一个二维数组FO(Free Output)。例如:
- FO[2][1] = 24677460
- FO[3][2] = 10321516

free的输出一共有四行,第四行为交换区的信息,分别是交换的总量(total),使用量(used)和有多少空闲的交换区(free)
free输出地第二行和第三行是比较让人迷惑的。这两行都是说明内存使用情况的
第一列是总量(total),第二列是使用量(used),第三列是可用量(free)
第一行的输出是从操作系统(OS)角度来看的。也就是说,从OS的角度来看,计算机上一共有:
- 24677460KB(缺省时free的单位为KB)物理内存,即FO[2][1];
- 在这些物理内存中有23276064KB(即FO[2][2])被使用了;
- 还用1401396KB(即FO[2][3])是可用的;
这里得到第一个等式:
- FO[2][1] = FO[2][2] + FO[2][3]
FO[2][4]表示被几个进程共享的内存量,现在已经deprecated,其值总是0(当然在一些系统上也可能不是0,主要取决于free命令是怎么实现的)
FO[2][5]表示被OS buffer住的内存。FO[2][6]表示被OS cache的内存。在有些时候buffer和cache这两个词经常混用。不过在一些比较低层的软件里是要区分这两个词的,看老外的洋文:
- A buffer is something that has yet to be “written” to disk.
- A cache is something that has been “read” from the disk and stored for later use.
也就是说buffer是用于存放要输出到disk(块设备)的数据的,而cache是存放从disk上读出的数据。这二者是为了提高IO性能的,并由OS管理
Linux和其他成熟的操作系统(例如windows),为了提高IO read的性能,总是要多cache一些数据,这也就是为什么FO[2][6](cached memory)比较大,而FO[2][3]比较小的原因。我们可以做一个简单的测试:
1、释放掉被系统cache占用的数据;
echo 3>/proc/sys/vm/drop_caches
2、读一个大文件,并记录时间;
3、关闭该文件;
4、重读这个大文件,并记录时间;
第二次读应该比第一次快很多
free输出的第二行是从一个应用程序的角度看系统内存的使用情况
- 对于FO[3][2],即-buffers/cache,表示一个应用程序认为系统被用掉多少内存;
- 对于FO[3][3],即+buffers/cache,表示一个应用程序认为系统还有多少内存;
因为被系统cache和buffer占用的内存可以被快速回收,所以通常FO[3][3]比FO[2][3]会大很多
这里还用两个等式:
- FO[3][2] = FO[2][2] - FO[2][5] - FO[2][6]
- FO[3][3] = FO[2][3] + FO[2][5] + FO[2][6]
补充:free命令的所有输出值都是从/proc/meminfo中读出的
IO
iostat
iostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息
1. 基本使用
$iostat -d -k 1 10
参数 -d 表示,显示设备(磁盘)使用状态;-k某些使用block为单位的列强制使用Kilobytes为单位;1 10表示,数据显示每隔1秒刷新一次,共显示10次
$iostat -d -k 1 10
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 39.29 21.14 1.44 441339807 29990031
sda1 0.00 0.00 0.00 1623 523
sda2 1.32 1.43 4.54 29834273 94827104
sda3 6.30 0.85 24.95 17816289 520725244
sda5 0.85 0.46 3.40 9543503 70970116
sda6 0.00 0.00 0.00 550 236
sda7 0.00 0.00 0.00 406 0
sda8 0.00 0.00 0.00 406 0
sda9 0.00 0.00 0.00 406 0
sda10 60.68 18.35 71.43 383002263 1490928140
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 327.55 5159.18 102.04 5056 100
sda1 0.00 0.00 0.00 0 0
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。“一次传输”请求的大小是未知的;
Indicate the number of transfers per second that were issued to the device. A transfer is an I/O request to the device. Multiple logical requests can be combined into a single I/O request to the device. A transfer is of indeterminate size.
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量;
kB_wrtn:写入的总数量数据量;
(这些单位都为Kilobytes)
上面的例子中,我们可以看到磁盘sda以及它的各个分区的统计数据,当时统计的磁盘总TPS是39.29,下面是各个分区的TPS。(因为是瞬间值,所以总TPS并不严格等于各个分区TPS的总和)
2. -x 参数
iostat还有一个比较常用的选项-x,该选项将用于显示和io相关的扩展数据
iostat -d -x -k 1 10
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 1.56 28.31 7.80 31.49 42.51 2.92 21.26 1.46 1.16 0.03 0.79 2.62 10.28
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 2.00 20.00 381.00 7.00 12320.00 216.00 6160.00 108.00 32.31 1.75 4.50 2.17 84.20
输出信息的含义
rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge);
The number of read requests merged per second that were queued to the device.
wrqm/s:每秒这个设备相关的写入请求有多少被Merge了;
The number of write requests merged per second that were queued to the device.
r/s:The number of read requests that were issued to the device per second;
w/s:The number of write requests that were issued to the device per second;
rsec/s:每秒读取的扇区数;
wsec/s:每秒写入的扇区数;
rkB/s:The number of kilobytes read from the device per second.
wkB/s:The number of kilobytes written to the device per second.
avgrq-sz:The average size (in sectors) of the requests that were issued to the device.
avgqu-sz:The average queue length of the requests that were issued to the device.
await:每一个IO请求的处理的平均时间(单位是毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了;
The average time (in milliseconds) for I/O requests issued to the device to be served. This includes the time spent by the requests in queue and the time spent servicing them.
svctm:表示平均每次设备I/O操作的服务时间(以毫秒为单位);
The average service time (in milliseconds) for I/O requests that were issued to the device. Warning! Do not trust this field any more. This field will be removed in a future sysstat version.
%util:在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈);
Percentage of CPU time during which I/O requests were issued to the device(bandwidth utilization for the device). Device saturation occurs when this value is close to 100%.
3. -c 参数
iostat还可以用来获取cpu部分状态值:
iostat -c 1 10
avg-cpu: %user %nice %sys %iowait %idle
1.98 0.00 0.35 11.45 86.22
avg-cpu: %user %nice %sys %iowait %idle
1.62 0.00 0.25 34.46 63.67
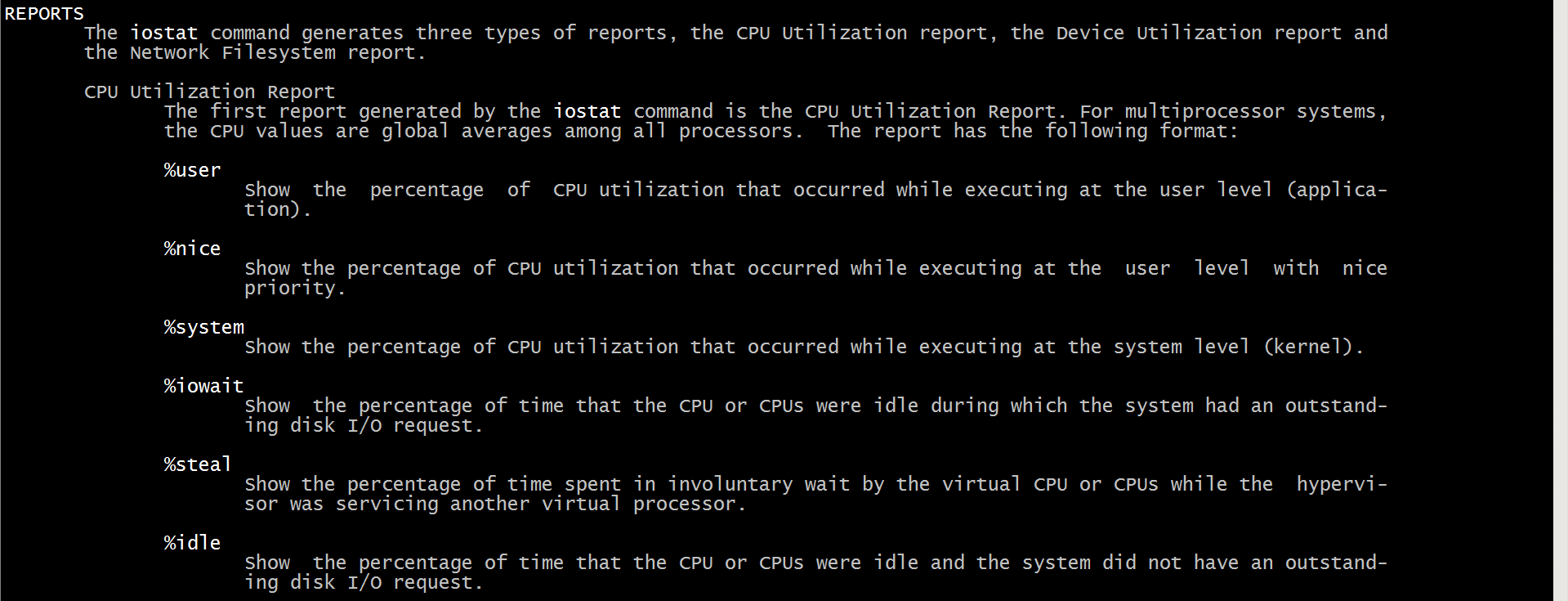
4. 常见用法
iostat -d -k 1 10 #查看TPS和吞吐量信息
iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await)
iostat -c 1 10 #查看cpu状态
5. 实例分析
$$iostat -d -k 1 |grep sda10
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda10 60.72 18.95 71.53 395637647 1493241908
sda10 299.02 4266.67 129.41 4352 132
sda10 483.84 4589.90 4117.17 4544 4076
sda10 218.00 3360.00 100.00 3360 100
sda10 546.00 8784.00 124.00 8784 124
sda10 827.00 13232.00 136.00 13232 136
上面看到,磁盘每秒传输次数平均约400;每秒磁盘读取约5MB,写入约1MB
iostat -d -x -k 1
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sda 1.56 28.31 7.84 31.50 43.65 3.16 21.82 1.58 1.19 0.03 0.80 2.61 10.29
sda 1.98 24.75 419.80 6.93 13465.35 253.47 6732.67 126.73 32.15 2.00 4.70 2.00 85.25
sda 3.06 41.84 444.90 54.08 14204.08 2048.98 7102.04 1024.49 32.57 2.10 4.21 1.85 92.24
可以看到磁盘的平均响应时间<5ms,磁盘使用率>80。磁盘响应正常,但是已经很繁忙了
Network
sar
查看网卡命令
ethtool eth1
sar输出
sar命令如下:
sar可用于网络监控,如下:
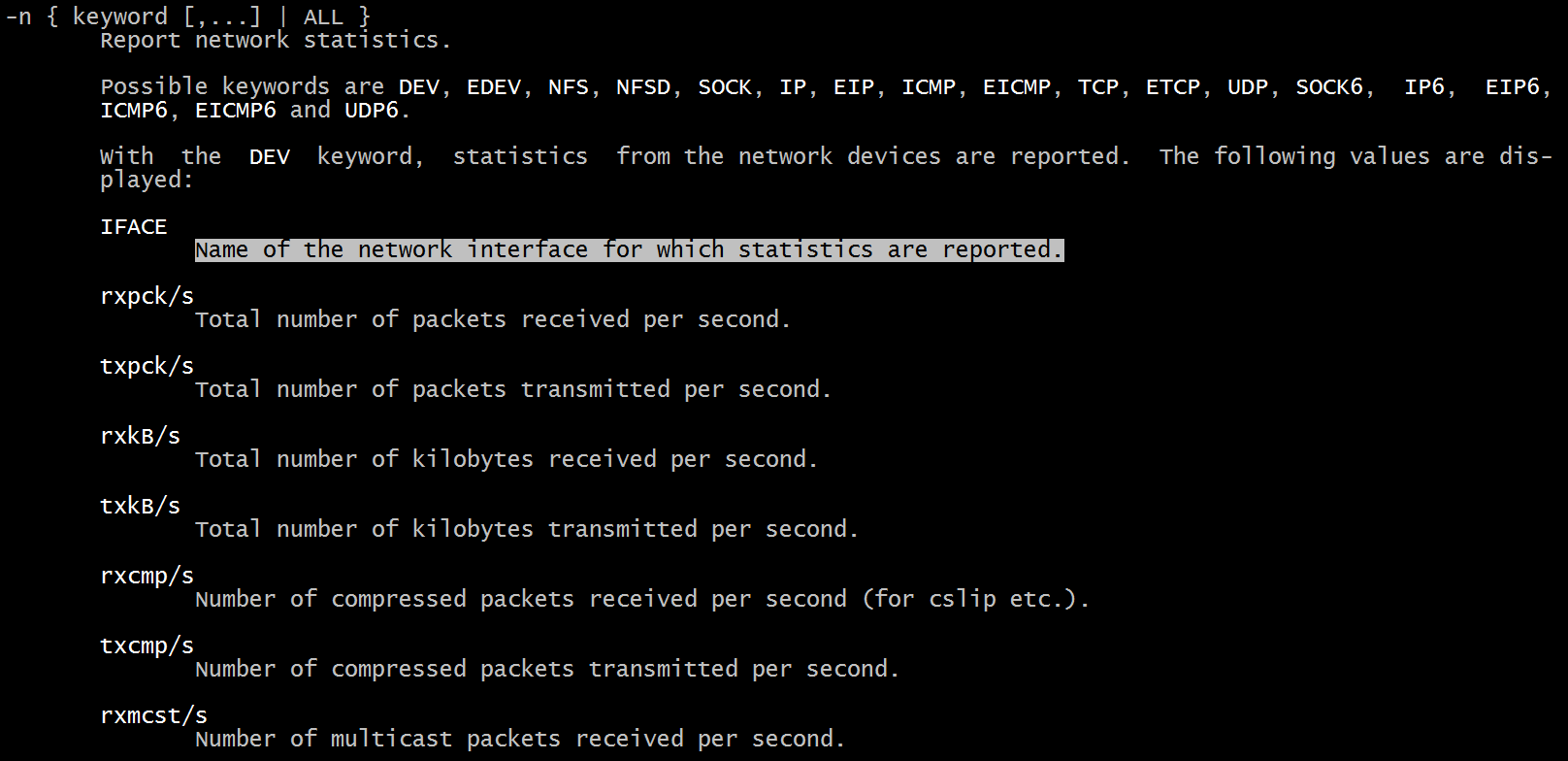
sar -n DEV 1输出如下:

输出信息的含义:
IFACE:网络设备名(网卡)
Name of the network interface for which statistics are reported.
rxpck/s:每秒接收的包
Total number of packets received per second.
txpck/s:每秒发送的包
Total number of packets transmitted per second.
rxkB/s:每秒接收的数据量
Total number of kilobytes received per second.
txkB/s: 每秒发送的数据量
Total number of kilobytes transmitted per second.
rxcmp/s:每秒接收的压缩数据包
Number of compressed packets received per second (for cslip etc.).
txcmp/s:每秒发送的压缩数据包
Number of compressed packets transmitted per second.
rxmcst/s:每秒接收的多播数据包
Number of multicast packets received per second.
参考
- top命令
- free命令
- iostat命令1
- iostat命令2
- Linux man iostat
- How Linux iostat Computes Metrics
- Linux iostat