由于Docker-registry涉及的知识和框架比较多,所以有必要对其进行梳理。主要是讲述和Docker-registry密切相关的知识以及它们之间的调用逻辑,达到对Docker-registry整体框架的一个比较清晰的了解
以Docker-registry为核心扩展,涉及的主要知识点包括:docker-registry、python-gunicorn、python-flask、python-gevent等
上述技术概述
下面分别介绍一下上述技术:
python-gunicorn采用pre-forker worker model,有一个master进程,它会fork多个worker进程,而这些worker进程共享一个Listener Socket,每个worker进程负责接受HTTP请求并处理,master进程只是负责利用TTIN、TTOU、CHLD等信号与worker进程通信并管理worker进程(例如:TTIN、TTOU、CHLD分别会触发master进程执行增加、减少、重启工作进程),另外每个worker进程在接受到HTTP请求后,需要加载APP对象(这个APP对象具有__call__方法,例如python-flask、django等WEB框架生成的APP对象)或者函数来执行HTTP的处理工作,将HTTP请求提取关键字(例如请求类型:GET、POST、HEAD ; 请求文件路径PATH 等)作为参数传递给APP对象或者函数,由它们来负责具体的HTTP请求处理逻辑以及操作,最后对HTTP请求回应报文进行再加工,并发送给客户端
python-flask是一个WEB框架,利用该框架可以很容易地构建WEB应用
docker-registry是一个典型的python-flask WEB应用。它是Docker hub的核心技术,所有研究的技术都围绕它展开。docker-registry主要是利用python-flask框架写一些HTTP请求处理逻辑。真正的HTTP处理逻辑和操作其实都在docker-registry中完成
python-gevent是一个基于协程的python网络库。如下是其简单描述:
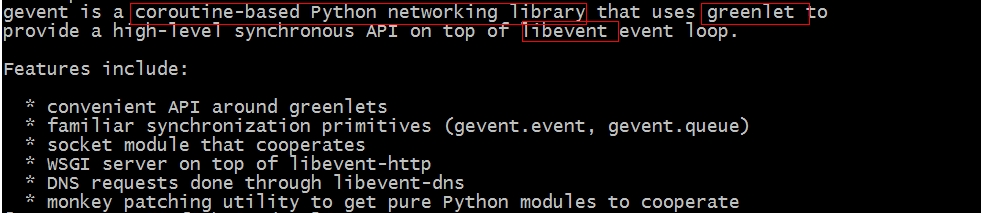
简单的讲就是利用python-greenlet提供协程支持,利用libevent提供事件触发,共同完成一个高性能的HTTP网络库。作为它的子技术:python-greenlet以及libevent,下面也简单描述一下:
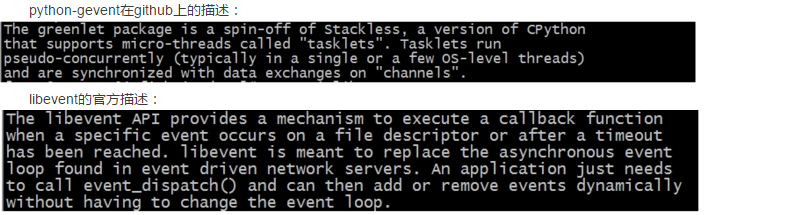
下面介绍上述技术的关系,上述技术之间的关系可以这样归纳:
docker-registry是利用python-flask写的WEB应用,负责真正的HTTP请求处理逻辑和操作
gunicorn框架中的worker进程会利用python-gevent作为HTTP处理框架,对每个HTTP请求它会加载docker-registry WEB APP对象进行具体处理,并对返回的回应报文加工,最后发送给客户端
下面是上述技术的接口图:

代码层面的理解
下面从代码层面加深上述的理解
首先启动docker-registry,由脚本启动,如下:
service docker-registry start
下面是/etc/init.d/docker-registry中的start函数
#!/bin/sh
#
# /etc/rc.d/init.d/docker-registry
#
# Registry server for Docker
#
# chkconfig: 2345 93 93
# description: Registry server for Docker
### BEGIN INIT INFO
# Provides: docker-registry
# Required-Start: $network
# Required-Stop:
# Should-Start:
# Should-Stop:
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: start and stop Docker registry
# Description: Registry server for Docker
### END INIT INFO
# Source function library.
. /etc/rc.d/init.d/functions
exec="/usr/bin/python"
prog="docker-registry"
pidfile="/var/run/$prog.pid"
lockfile="/var/lock/subsys/$prog"
logfile="/var/log/$prog"
[ -e /etc/sysconfig/$prog ] && . /etc/sysconfig/$prog
export DOCKER_REGISTRY_CONFIG=${DOCKER_REGISTRY_CONFIG:-"/etc/docker-registry.yml"}
export SETTINGS_FLAVOR=${SETTINGS_FLAVOR:-"dev"}
start() {
[ -x $exec ] || exit 5
if ! [ -f $pidfile ]; then
cd /usr/lib/python2.6/site-packages/docker-registry
printf "Starting $prog:\t"
$exec /usr/bin/gunicorn --access-logfile - --debug --max-requests 100 --graceful-timeout 3600 -t 3600 -k gevent -b ${REGISTRY_ADDRESS}:${REGISTRY_PORT} -w $GUNICORN_WORKERS docker_registry.wsgi:application &>> $logfile &
pid=$!
echo $pid > $pidfile
touch $lockfile
success
echo
else
failure
echo
printf "$pidfile still exists...\n"
exit 7
fi
}
很容易看出入口为/usr/bin/gunicorn,下面是/usr/bin/gunicorn的文件内容:
#!/usr/bin/python
# EASY-INSTALL-ENTRY-SCRIPT: 'gunicorn==18.0','console_scripts','gunicorn'
__requires__ = 'gunicorn==18.0'
import sys
from pkg_resources import load_entry_point
if __name__ == '__main__':
sys.exit(
load_entry_point('gunicorn==18.0', 'console_scripts', 'gunicorn')()
)
# -*- coding: utf-8 -
#
# This file is part of gunicorn released under the MIT license.
# See the NOTICE for more information.
import os
import sys
from gunicorn.errors import ConfigError
from gunicorn.app.base import Application
from gunicorn.app import djangoapp
from gunicorn import util
class WSGIApplication(Application):
def init(self, parser, opts, args):
if opts.paste and opts.paste is not None:
path = os.path.abspath(os.path.normpath(
os.path.join(util.getcwd(), opts.paste)))
if not os.path.exists(path):
raise ConfigError("%r not found" % val)
# paste application, load the config
self.cfgurl = 'config:%s' % path
self.relpath = os.path.dirname(path)
from .pasterapp import paste_config
return paste_config(self.cfg, self.cfgurl, self.relpath)
if len(args) != 1:
parser.error("No application module specified.")
self.cfg.set("default_proc_name", args[0])
self.app_uri = args[0]
def chdir(self):
# chdir to the configured path before loading,
# default is the current dir
os.chdir(self.cfg.chdir)
# add the path to sys.path
sys.path.insert(0, self.cfg.chdir)
def load_wsgiapp(self):
self.chdir()
# load the app
return util.import_app(self.app_uri)
def load_pasteapp(self):
self.chdir()
# load the paste app
from .pasterapp import load_pasteapp
return load_pasteapp(self.cfgurl, self.relpath, global_conf=None)
def load(self):
if self.cfg.paste is not None:
return self.load_pasteapp()
else:
return self.load_wsgiapp()
def run():
"""\
The ``gunicorn`` command line runner for launching Ghunicorn with
generic WSGI applications.
"""
from gunicorn.app.wsgiapp import WSGIApplication
WSGIApplication("%(prog)s [OPTIONS] [APP_MODULE]").run()
if __name__ == '__main__':
run()
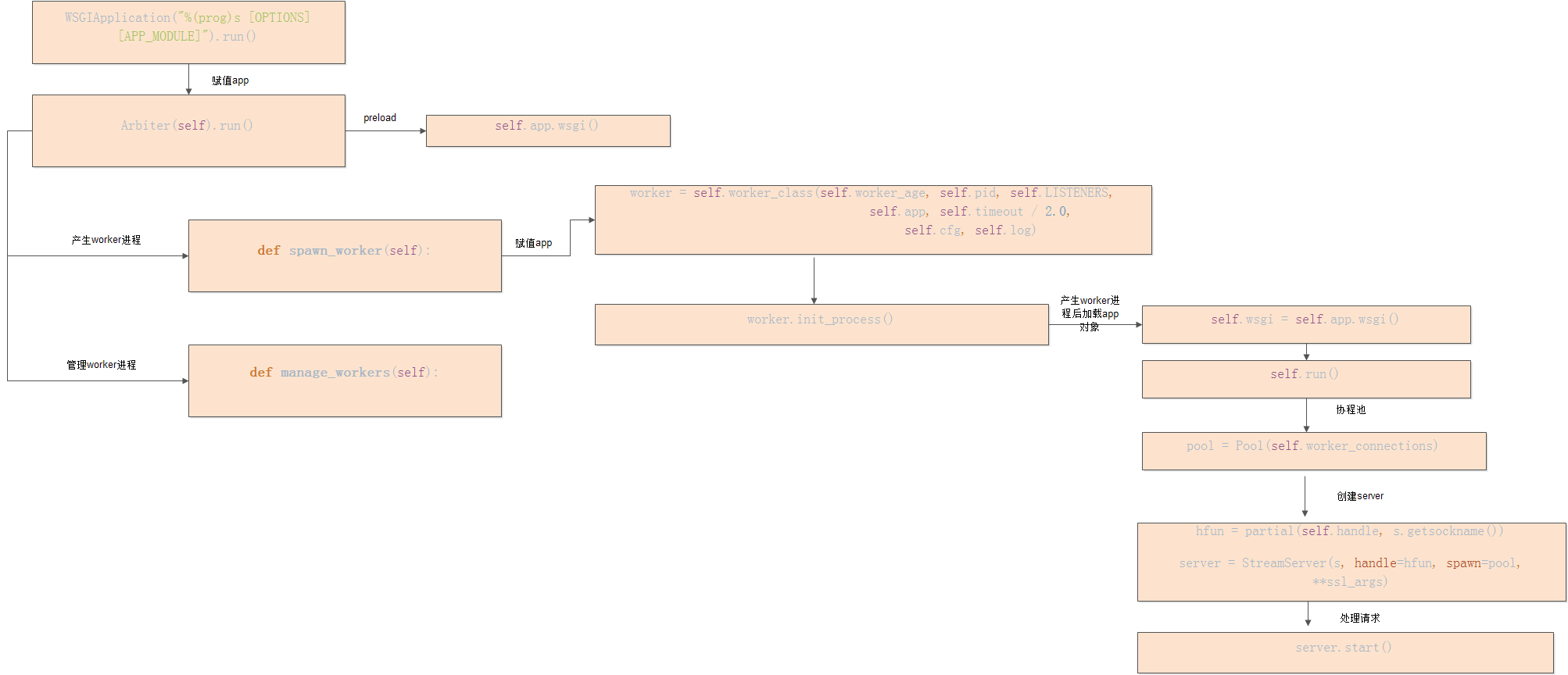
python-gunicorn入口是wsgiapp.py的run函数。逻辑很清晰:加载WSGIApplication类,生成该对象,并执行run函数。再回去看/etc/init.d/docker-registry启动脚本中的参数:
$exec /usr/bin/gunicorn --access-logfile - --debug --max-requests 100 --graceful-timeout 3600 -t 3600 -k gevent -b ${REGISTRY_ADDRESS}:${REGISTRY_PORT} -w $GUNICORN_WORKERS docker_registry.wsgi:application &>> $logfile &
可以将这些参数分为三类,分别对应prog、OPTIONS、APP_MODULE,如下:
prog:/usr/bin/gunicorn
OPTIONS:--access-logfile - --debug --max-requests 100 --graceful-timeout 3600 -t 3600 -k gevent -b ${REGISTRY_ADDRESS}:${REGISTRY_PORT} -w $GUNICORN_WORKERS
APP_MODULE:docker_registry.wsgi:application
这些参数将作为WSGIApplication构造函数的参数,如下:
WSGIApplication("%(prog)s [OPTIONS] [APP_MODULE]").run()
WSGIApplication类继承Application类,如下:
...
from gunicorn.app.base import Application
from gunicorn.app import djangoapp
from gunicorn import util
class WSGIApplication(Application):
...
所以,WSGIApplication对象会执行Application的run函数,该函数会生成Arbiter对象,并执行该对象的run函数,如下:
def run(self):
if self.cfg.check_config:
try:
self.load()
except:
sys.stderr.write("\nError while loading the application:\n\n")
traceback.print_exc()
sys.stderr.flush()
sys.exit(1)
sys.exit(0)
if self.cfg.spew:
debug.spew()
if self.cfg.daemon:
util.daemonize(self.cfg.enable_stdio_inheritance)
# set python paths
if self.cfg.pythonpath and self.cfg.pythonpath is not None:
paths = self.cfg.pythonpath.split(",")
for path in paths:
pythonpath = os.path.abspath(path)
if pythonpath not in sys.path:
sys.path.insert(0, pythonpath)
try:
Arbiter(self).run()
except RuntimeError as e:
sys.stderr.write("\nError: %s\n\n" % e)
sys.stderr.flush()
sys.exit(1)
而Arbiter类的run函数则是整个python-gunicorn的核心,它会生成worker进程,如下:
def run(self):
"Main master loop."
self.start()
util._setproctitle("master [%s]" % self.proc_name)
self.manage_workers()
while True:
try:
self.reap_workers()
sig = self.SIG_QUEUE.pop(0) if len(self.SIG_QUEUE) else None
if sig is None:
self.sleep()
self.murder_workers()
self.manage_workers()
continue
if sig not in self.SIG_NAMES:
self.log.info("Ignoring unknown signal: %s", sig)
continue
signame = self.SIG_NAMES.get(sig)
handler = getattr(self, "handle_%s" % signame, None)
if not handler:
self.log.error("Unhandled signal: %s", signame)
continue
self.log.info("Handling signal: %s", signame)
handler()
self.wakeup()
except StopIteration:
self.halt()
except KeyboardInterrupt:
self.halt()
except HaltServer as inst:
self.halt(reason=inst.reason, exit_status=inst.exit_status)
except SystemExit:
raise
except Exception:
self.log.info("Unhandled exception in main loop:\n%s",
traceback.format_exc())
self.stop(False)
if self.pidfile is not None:
self.pidfile.unlink()
sys.exit(-1)
manage_workers函数用于生成worker进程或者kill worker进程,使工作进程总数保持不变,如下:
def manage_workers(self):
"""\
Maintain the number of workers by spawning or killing
as required.
"""
if len(self.WORKERS.keys()) < self.num_workers:
self.spawn_workers()
workers = self.WORKERS.items()
workers = sorted(workers, key=lambda w: w[1].age)
while len(workers) > self.num_workers:
(pid, _) = workers.pop(0)
self.kill_worker(pid, signal.SIGQUIT)
其中spawn_workers用于生成worker进程,kill_worker用于杀死工作进程,稍后详细介绍spawn_workers函数的逻辑
同时,Arbiter类的run函数也负责管理worker进程,如下:
def run(self):
"Main master loop."
self.start()
util._setproctitle("master [%s]" % self.proc_name)
self.manage_workers()
while True:
try:
self.reap_workers()
sig = self.SIG_QUEUE.pop(0) if len(self.SIG_QUEUE) else None
if sig is None:
self.sleep()
self.murder_workers()
self.manage_workers()
continue
if sig not in self.SIG_NAMES:
self.log.info("Ignoring unknown signal: %s", sig)
continue
signame = self.SIG_NAMES.get(sig)
handler = getattr(self, "handle_%s" % signame, None)
if not handler:
self.log.error("Unhandled signal: %s", signame)
continue
self.log.info("Handling signal: %s", signame)
handler()
self.wakeup()
except StopIteration:
self.halt()
except KeyboardInterrupt:
self.halt()
except HaltServer as inst:
self.halt(reason=inst.reason, exit_status=inst.exit_status)
except SystemExit:
raise
except Exception:
self.log.info("Unhandled exception in main loop:\n%s",
traceback.format_exc())
self.stop(False)
if self.pidfile is not None:
self.pidfile.unlink()
sys.exit(-1)
master进程会进入无限循环,利用信号与worker进程通信,从而管理worker进程,这里不展开介绍
下面详细介绍worker进程产生过程,也即函数`spawn_workers`,该函数首先创建worker_class对象,python-gunicorn中总共有四种类型的[worker类型](http://docs.gunicorn.org/en/latest/design.html),如下:
- Sync Workers
The most basic and the default worker type is a synchronous worker class that handles a single request at a time. This model is the simplest to reason about as any errors will affect at most a single request. Though as we describe below only processing a single request at a time requires some assumptions about how applications are programmed.
- Async Workers
The asynchronous workers available are based on Greenlets (via Eventlet and Gevent). Greenlets are an implementation of cooperative multi-threading for Python. In general, an application should be able to make use of these worker classes with no changes.
- Tornado Workers
There’s also a Tornado worker class. It can be used to write applications using the Tornado framework. Although the Tornado workers are capable of serving a WSGI application, this is not a recommended configuration.
- AsyncIO Workers
These workers are compatible with python3. You have two kind of workers.
The worker gthread is a threaded worker. It accepts connections in the main loop, accepted connections are added to the thread pool as a connection job. On keepalive connections are put back in the loop waiting for an event. If no event happen after the keep alive timeout, the connection is closed.
The worker gaiohttp is a full asyncio worker using aiohttp.
其中`AsyncIO Workers`是推荐的worker类型,在如下情况要求使用该worker类型:
- Choosing a Worker Type
The default synchronous workers assume that your application is resource-bound in terms of CPU and network bandwidth. Generally this means that your application shouldn’t do anything that takes an undefined amount of time. An example of something that takes an undefined amount of time is a request to the internet. At some point the external network will fail in such a way that clients will pile up on your servers. So, in this sense, any web application which makes outgoing requests to APIs will benefit from an asynchronous worker.
This resource bound assumption is why we require a buffering proxy in front of a default configuration Gunicorn. If you exposed synchronous workers to the internet, a DOS attack would be trivial by creating a load that trickles data to the servers. For the curious, Hey is an example of this type of load.
Some examples of behavior requiring asynchronous workers:
- Applications making long blocking calls (Ie, external web services)
- Serving requests directly to the internet
- Streaming requests and responses
- Long polling
- Web sockets
- Comet
回顾开始,启动脚本中其实已经指定了是使用AsyncIO Workers进程的,如下:
--access-logfile - --debug --max-requests 100 --graceful-timeout 3600 -t 3600 -k gevent -b ${REGISTRY_ADDRESS}:${REGISTRY_PORT} -w $GUNICORN_WORKERS
就是由-k选项指定工作进程类型,gevent表示`AsyncIO Workers`类型
python-gunicorn中与该worker进程对应的处理类是gunicorn/workers/ggevent.py中GeventWorker类,也即spawn_workers函数会生成GeventWorker类对象
在生成GeventWorker类对象后,spawn_workers函数会fork子进程(也即worker进程),子进程会执行该GeventWorker类对象的init_process函数,如下:
def spawn_worker(self):
self.worker_age += 1
worker = self.worker_class(self.worker_age, self.pid, self.LISTENERS,
self.app, self.timeout / 2.0,
self.cfg, self.log)
self.cfg.pre_fork(self, worker)
pid = os.fork()
if pid != 0:
self.WORKERS[pid] = worker
return pid
# Process Child
worker_pid = os.getpid()
try:
util._setproctitle("worker [%s]" % self.proc_name)
self.log.info("Booting worker with pid: %s", worker_pid)
self.cfg.post_fork(self, worker)
worker.init_process()
sys.exit(0)
except SystemExit:
raise
except AppImportError as e:
self.log.debug("Exception while loading the application: \n%s",
traceback.format_exc())
sys.stderr.write("%s\n" % e)
sys.stderr.flush()
sys.exit(self.APP_LOAD_ERROR)
except:
self.log.exception("Exception in worker process:\n%s",
traceback.format_exc())
if not worker.booted:
sys.exit(self.WORKER_BOOT_ERROR)
sys.exit(-1)
finally:
self.log.info("Worker exiting (pid: %s)", worker_pid)
try:
worker.tmp.close()
self.cfg.worker_exit(self, worker)
except:
pass
init_process函数会调用GeventWorker类的run函数,该函数对每个Listener Socket(监听套接字)会分别创建一个python-gevent中的StreamServer类对象,并执行start函数,如下:
if gevent.version_info[0] == 0:
def init_process(self):
#gevent 0.13 and older doesn't reinitialize dns for us after forking
#here's the workaround
import gevent.core
gevent.core.dns_shutdown(fail_requests=1)
gevent.core.dns_init()
super(GeventWorker, self).init_process()
def init_process(self):
"""\
If you override this method in a subclass, the last statement
in the function should be to call this method with
super(MyWorkerClass, self).init_process() so that the ``run()``
loop is initiated.
"""
# set enviroment' variables
if self.cfg.env:
for k, v in self.cfg.env.items():
os.environ[k] = v
util.set_owner_process(self.cfg.uid, self.cfg.gid)
# Reseed the random number generator
util.seed()
# For waking ourselves up
self.PIPE = os.pipe()
for p in self.PIPE:
util.set_non_blocking(p)
util.close_on_exec(p)
# Prevent fd inherientence
[util.close_on_exec(s) for s in self.sockets]
util.close_on_exec(self.tmp.fileno())
self.log.close_on_exec()
self.init_signals()
self.wsgi = self.app.wsgi()
self.cfg.post_worker_init(self)
# Enter main run loop
self.booted = True
self.run()
def run(self):
servers = []
ssl_args = {}
if self.cfg.is_ssl:
ssl_args = dict(server_side=True,
do_handshake_on_connect=False, **self.cfg.ssl_options)
for s in self.sockets:
s.setblocking(1)
pool = Pool(self.worker_connections)
if self.server_class is not None:
server = self.server_class(
s, application=self.wsgi, spawn=pool, log=self.log,
handler_class=self.wsgi_handler, **ssl_args)
else:
hfun = partial(self.handle, s.getsockname())
server = StreamServer(s, handle=hfun, spawn=pool, **ssl_args)
server.start()
servers.append(server)
try:
while self.alive:
self.notify()
gevent.sleep(1.0)
except KeyboardInterrupt:
pass
except:
try:
server.stop()
except:
pass
raise
try:
# Stop accepting requests
for server in servers:
if hasattr(server, 'close'): # gevent 1.0
server.close()
if hasattr(server, 'kill'): # gevent < 1.0
server.kill()
# Handle current requests until graceful_timeout
ts = time.time()
while time.time() - ts <= self.cfg.graceful_timeout:
accepting = 0
for server in servers:
if server.pool.free_count() != server.pool.size:
accepting += 1
# if no server is accepting a connection, we can exit
if not accepting:
return
self.notify()
gevent.sleep(1.0)
# Force kill all active the handlers
self.log.warning("Worker graceful timeout (pid:%s)" % self.pid)
[server.stop(timeout=1) for server in servers]
except:
pass
由于server_class为None,则会执行else分支,也即会生成python-gevent中的StreamServer类对象,其中pool可以理解为利用python-greenlet生成的协程池。之后启动该对象的start函数
接下来详细介绍一下StreamServer类对象的start函数,如下:
def start(self):
"""Start accepting the connections.
If an address was provided in the constructor, then also create a socket, bind it and put it into the listening mode.
"""
assert not self.started, '%s already started' % self.__class__.__name__
self.pre_start()
self.started = True
try:
self.start_accepting()
except:
self.kill()
raise
该函数会调用start_accepting函数,转到start_accepting函数,如下:
def start_accepting(self):
if self._accept_event is None:
self._accept_event = core.read_event(self.socket.fileno(), self._do_accept, persist=True)
该函数会利用Libevent在监听套接字上创建一个触发事件,只要有客户端请求到来则会触发调用_do_accept函数,转到_do_accept函数,如下:
def _do_accept(self, event, _evtype):
assert event is self._accept_event
for _ in xrange(self.max_accept):
address = None
try:
if self.full():
self.stop_accepting()
return
try:
client_socket, address = self.socket.accept()
except socket.error, err:
if err[0] == EWOULDBLOCK:
return
raise
self.delay = self.min_delay
client_socket = socket.socket(_sock=client_socket)
spawn = self._spawn
if spawn is None:
self._handle(client_socket, address)
else:
spawn(self._handle, client_socket, address)
except:
traceback.print_exc()
ex = sys.exc_info()[1]
if self.is_fatal_error(ex):
self.kill()
sys.stderr.write('ERROR: %s failed with %s\n' % (self, str(ex) or repr(ex)))
return
try:
if address is None:
sys.stderr.write('%s: Failed.\n' % (self, ))
else:
sys.stderr.write('%s: Failed to handle request from %s\n' % (self, address, ))
except Exception:
traceback.print_exc()
if self.delay >= 0:
self.stop_accepting()
self._start_accepting_timer = core.timer(self.delay, self.start_accepting)
self.delay = min(self.max_delay, self.delay * 2)
return
该函数会accept请求,创建Client Socket,并创建线程处理该客户端请求,而这里的self._handle也即python-gunicorn中GeventWorker类的handle函数,跳转到handle函数,如下:
def handle(self, listener, client, addr):
req = None
try:
parser = http.RequestParser(self.cfg, client)
try:
if not self.cfg.keepalive:
req = six.next(parser)
self.handle_request(listener, req, client, addr)
else:
# keepalive loop
while True:
req = None
with self.timeout_ctx():
req = six.next(parser)
if not req:
break
self.handle_request(listener, req, client, addr)
except http.errors.NoMoreData as e:
self.log.debug("Ignored premature client disconnection. %s", e)
except StopIteration as e:
self.log.debug("Closing connection. %s", e)
except ssl.SSLError:
raise # pass to next try-except level
except socket.error:
raise # pass to next try-except level
except Exception as e:
self.handle_error(req, client, addr, e)
except ssl.SSLError as e:
if e.args[0] == ssl.SSL_ERROR_EOF:
self.log.debug("ssl connection closed")
client.close()
else:
self.log.debug("Error processing SSL request.")
self.handle_error(req, client, addr, e)
except socket.error as e:
if e.args[0] not in (errno.EPIPE, errno.ECONNRESET):
self.log.exception("Socket error processing request.")
else:
if e.args[0] == errno.ECONNRESET:
self.log.debug("Ignoring connection reset")
else:
self.log.debug("Ignoring EPIPE")
except Exception as e:
self.handle_error(req, client, addr, e)
finally:
util.close(client)
该函数负责请求的处理,三个参数分别表示:监听套接字、连接套接字,客户端地址
处理逻辑为:首先分析请求内容,然后交给handle_request函数处理
转到handle_request函数,如下:
def handle_request(self, listener_name, req, sock, addr):
request_start = datetime.now()
environ = {}
resp = None
try:
self.cfg.pre_request(self, req)
resp, environ = wsgi.create(req, sock, addr,
listener_name, self.cfg)
self.nr += 1
if self.alive and self.nr >= self.max_requests:
self.log.info("Autorestarting worker after current request.")
resp.force_close()
self.alive = False
if not self.cfg.keepalive:
resp.force_close()
respiter = self.wsgi(environ, resp.start_response)
if respiter == ALREADY_HANDLED:
return False
try:
if isinstance(respiter, environ['wsgi.file_wrapper']):
resp.write_file(respiter)
else:
for item in respiter:
resp.write(item)
resp.close()
request_time = datetime.now() - request_start
self.log.access(resp, req, environ, request_time)
finally:
if hasattr(respiter, "close"):
respiter.close()
if resp.should_close():
raise StopIteration()
except Exception:
if resp and resp.headers_sent:
# If the requests have already been sent, we should close the
# connection to indicate the error.
try:
sock.shutdown(socket.SHUT_RDWR)
sock.close()
except socket.error:
pass
raise StopIteration()
raise
finally:
try:
self.cfg.post_request(self, req, environ, resp)
except Exception:
self.log.exception("Exception in post_request hook")
return True
该函数会加载Docker-registry app对象,并执行`__call__`函数,如下:(这个很关键,是python-gunicorn与docker-registry联系所在)
respiter = self.wsgi(environ, resp.start_response)
self.wsgi也即Docker-registry的App对象,回到最开始的脚本文件,APP模块为:docker_registry.wsgi:application,转到Docker-registry的wsgi.py文件:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# only needed if not using gunicorn gevent
if __name__ == '__main__':
import gevent.monkey
gevent.monkey.patch_all()
# start new relic if instructed to do so
from .extensions import factory
from .extras import enewrelic
from .server import env
enewrelic.boot(env.source('NEW_RELIC_CONFIG_FILE'),
env.source('NEW_RELIC_LICENSE_KEY'))
factory.boot()
import logging
from .app import app # noqa
from .tags import * # noqa
from .images import * # noqa
from .lib import config
cfg = config.load()
if cfg.search_backend:
from .search import * # noqa
if cfg.standalone:
# If standalone mode is enabled, load the fake Index routes
from .index import * # noqa
if __name__ == '__main__':
host = env.source('REGISTRY_HOST')
port = env.source('REGISTRY_PORT')
app.debug = cfg.debug
app.run(host=host, port=port)
else:
level = cfg.loglevel.upper()
if not hasattr(logging, level):
level = 'INFO'
level = getattr(logging, level)
app.logger.setLevel(level)
stderr_logger = logging.StreamHandler()
stderr_logger.setLevel(level)
stderr_logger.setFormatter(
logging.Formatter('%(asctime)s %(levelname)s: %(message)s'))
app.logger.addHandler(stderr_logger)
application = app
其中app为Flask类对象,如下:
app = flask.Flask('docker-registry')
之后,会调用Flask类对象的__call__函数(在python-flask中),如下:
def __call__(self, environ, start_response):
"""Shortcut for :attr:`wsgi_app`."""
return self.wsgi_app(environ, start_response)
该函数会调用wsgi_app函数,其中environ为WSGI HTTP环境,主要包含请求类型(例如:GET、POST等)和请求文件URI;start_response则主要负责重加工请求回应的头部信息,最后返回值即为回应的内容
wsgi_app函数处理逻辑大致为:先从environ中取出请求类型和请求文件URI,然后根据这两个主要参数调用对应的函数处理,并生成回应报文,之后,调用start_response函数重加工回应报文头部,最后将回应内容作为函数返回值返回
最后handle_request函数还要将请求信息写入日志,如下:
self.log.access(resp, req, environ, request_time)
这样整个Docker-registry的框架就大致讲完了,以后会陆续补充,欢迎大家讨论!
补充
如下是docker-registry原理流程图: