前言
大家好,我叫杜杨浩,很高兴今天在这里给大家分享一下Kubernetes集群高可用&备份还原方案。无论是高可用还是备份还原都是生产环境所必须具备的特性,本次分享将依次介绍我在实现这些特性过程中遇到的问题,以及相应的思考和解决方案。
Kubernetes高可用实战
对于Kubernetes集群高可用,这里主要指母机宕机情况下的高可用方案。我将依次从高可用架构,母机宕机下的网络影响,存储影响,应用高可用以及Pod驱逐(服务恢复)等角度对集群高可用进行系统阐述,并在最后给出一个实战总结。
高可用架构
- control plane node
如下给出了Kubernetes社区采用kubeadm搭建的3节点高可用集群架构图(Stacked etcd topology):

该方案中,所有管理节点都部署kube-apiserver,kube-controller-manager,kube-scheduler,以及etcd等组件;kube-apiserver均与本地的etcd进行通信,etcd在三个节点间同步数据并构成高可用集群;而kube-controller-manager和kube-scheduler也只与本地的kube-apiserver进行通信(或者通过LB访问)
kube-apiserver前面顶一个LB;work节点kubelet以及kube-proxy组件对接LB访问apiserver
在这种架构中,如果其中任意一个master节点宕机了,由于kube-controller-manager以及kube-scheduler基于Leader Election Mechanism实现了高可用,可以认为管理集群不受影响,相关组件依旧正常运行(在分布式锁释放后)
- work node
工作节点上部署应用,应用按照反亲和部署多个副本,使副本调度在不同的work node上,这样如果其中一个副本所在的母机宕机了,理论上通过Kubernetes service可以把请求切换到另外副本上,使服务依旧可用
母机宕机下的网络影响
问题1:service backend剔除
首先我们介绍一下母机宕机下的网络影响。如下给出了Kubernetes service的两种代理模式:
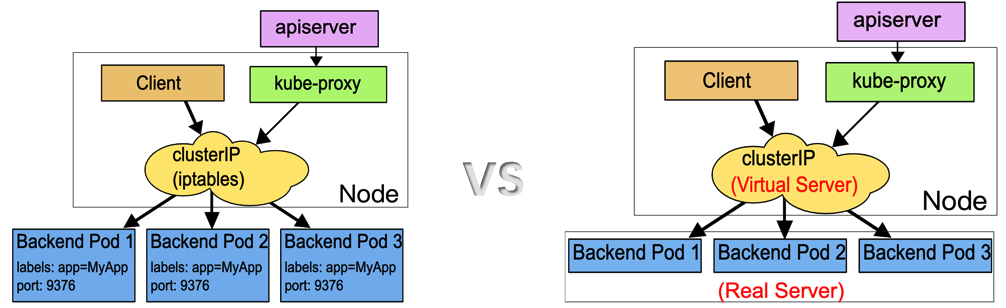
这两种代理模式都采用了linux kernel netfilter hook function。区别在于iptables代理模式使用的是iptables的DNAT规则实现service的负载均衡;而IPVS底层使用了hash数据结构,通过调用netlink接口创建IPVS规则实现负载均衡。与iptables相比,IPVS模式具备更低的网络延时,更高的规则同步效率以及更丰富的负载均衡选项
我们知道Kubernetes是通过节点心跳来保证节点健康状态的,每个node在kube-node-lease namespace下会对应一个Lease object,kubelet每隔node-status-update-frequency时间(默认10s)会更新对应node的Lease object,超过一定时间没有更新,node-controller会将节点标记为ConditionUnknown状态,并将该母机上的pod从相应service的后端列表中给剔除掉
也就是说在node-monitor-grace-period(默认40s)时间内,iptables&IPVS代理模式下的k8s service对应的ep不会剔除宕机母机上的pod,访问会出现间歇性问题(负载均衡轮询机制)
解决方案
对于这个问题,我们可以尝试调整Kubernetes参数将访问异常间隔缩短:
(kubelet)node-status-update-frequency:default 10s
(kube-controller-manager)node-monitor-period:default 5s
(kube-controller-manager)node-monitor-grace-period:default 40s
Amount of time which we allow running Node to be unresponsive before marking it unhealthy. Must be N times more than kubelet's nodeStatusUpdateFrequency, where N means number of retries allowed for kubelet to post node status.
- Currently nodeStatusUpdateRetry is constantly set to 5 in kubelet.go
问题2: TCP长连接超时
接下来我们探讨一下母机宕机下的另外一个网络问题:TCP长连接超时。之前我写过一篇文章详细描述这个问题,感兴趣的读者可以深入看看Kubernetes Controller高可用诡异的15mins超时
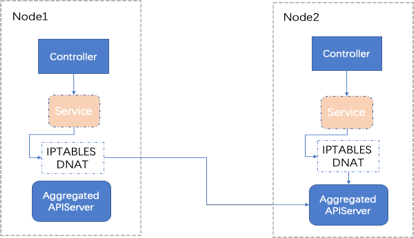
可以看到上图中两个母机分别部署了Controller和Aggregated APIServer服务,Controller通过service访问AA(Aggregated APIServer),且两台母机上Controller都是访问的Node2的AA pod,假设在某一时刻Node2宕机了,按照正常的理解,Node1上的Controller会在分布式锁被释放后获取锁并启动正常逻辑
但是观察到的现象是Node1上的Controller会一直尝试获取锁,并且超时,整个过程持续15mins左右。
这个问题的原因可以归纳如下:
- 母机宕机后,无法及时发送RST包给请求对端
- HTTP/2在请求超时后并不会关闭底层TCP连接,而是会继续复用(HTTP/1在请求超时后会关闭TCP连接)。TCP ARQ机制导致了上述的15mins超时现象
- 本质是应用没有对TCP Socket设置超时&健康检查
Kubernetes集群中几乎所有使用client-go的应用(kubelet除外)都会出现上述15mins超时问题。虽然可以简单采用禁用HTTP/2切换HTTP/1同时设置请求超时的方法进行规避,但却无法解决推送类服务(Watch)的超时问题(如果设置了超时,正常情况下Watch会超时)
而Kubernetes社区也对应存在着类似的client-go issue,至今依然处于Open的状态,问题一直没有解决
解决方案
对于这个问题,我们可以从多个角度进行思考和解决:
- 代码角度
从代码角度来看,我们可以通过对应用层使用超时设置或者健康检查机制,从上层保障连接的健康状态 - 作用于该应用
举例来说,对于HTTP/1的应用需要设置请求超时;而对于HTTP/2的应用,为了解决HTTP/2无法及时移除异常连接的问题,我分别给golang/net以及k8s.io/apimachinery提交了PR,用于设置HTTP/2的健康检查,目前均等待Merged中
- 工程角度
从工程的角度,一方面我们可以调整TCP ARQ&keepalive参数来缩短异常连接关闭的时间:
# /etc/sysctl.conf
net.ipv4.tcp_keepalive_time=30
net.ipv4.tcp_keepalive_intvl=30
net.ipv4.tcp_keepalive_probes=5
net.ipv4.tcp_retries2=9
$ /sbin/sysctl -p
在Kubernetes环境中,由于容器不会直接继承母机tcp keepalive的配置(可以直接继承母机tcp超时重试的配置),因此必须通过一定方式进行适配。这里介绍其中一种方式,添加initContainers使配置生效:
- name: init-sysctl
image: busybox
command:
- /bin/sh
- -c
- |
sysctl -w net.ipv4.tcp_keepalive_time=30
sysctl -w net.ipv4.tcp_keepalive_intvl=30
sysctl -w net.ipv4.tcp_keepalive_probes=5
securityContext:
privileged: true
另一方面,我们可以采用调整服务部署架构的方式规避该问题。这里介绍其中一种方案 - Kubernetes服务拓扑感知:
这里利用了Kubernetes服务拓扑感知规则[“kubernetes.io/hostname”,“*”]:优先使用同一节点上的端点,如果该节点上没有可用端点,则回退到任何可用端点上
通过如上的规则,我们将client和server进行捆绑安装,同一个母机上的client永远只访问本地的server(除非本地server挂掉),如下:
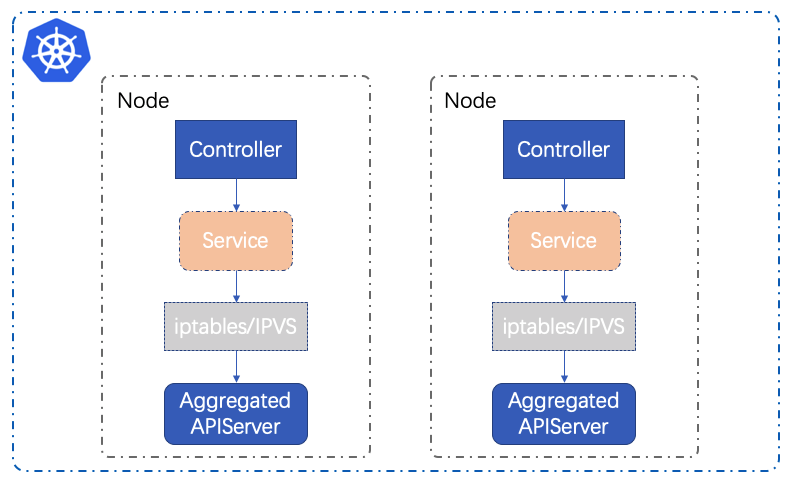
这样即便存在母机宕机,对其它母机上的服务也没有任何影响
上述提出的三种解决方案可以结合起来一起使用,使得整个集群在母机宕机情况下网络异常时间控制在一个比较短的时间内。当然了,如果使用的是外部LB而非Kubernetes默认提供的service类型,则可以利用外接LB自身的高可用&负载均衡机制进行规避。
母机宕机下的存储影响
对于存储,我们将Kubernetes集群存储分为系统存储和应用存储,系统存储专指etcd;而应用存储一般来说只考虑persistent volume。接下来将依次进行介绍:
- 母机宕机下的存储影响 - 系统存储
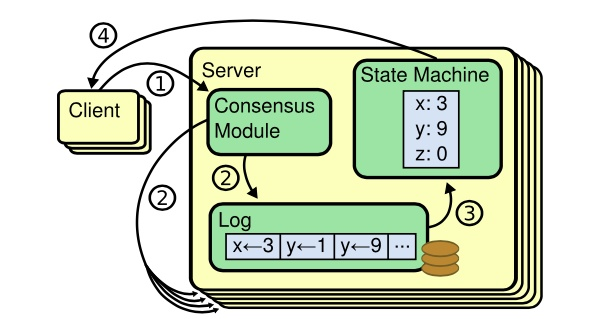
Kubernetes系统存储专指etcd,而etcd使用Raft一致性算法(leader selection + log replication + safety)中的leader selection来实现节点宕机下的高可用问题,如下:
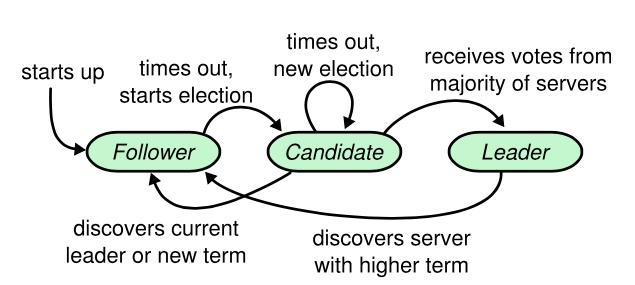
- 母机宕机下的存储影响 - 应用存储
这里考虑存储是部署在集群外的情况(通常情况)。如果一个母机宕机了,由于没有对外部存储集群产生破坏,因此不会影响其它母机上应用访问pv存储
而对于Kubernetes存储本身组件功能(in-tree, flexVolume, external-storage以及csi)的影响实际上可以归纳为对存储插件应用的影响,这里以csi为例子进行说明:
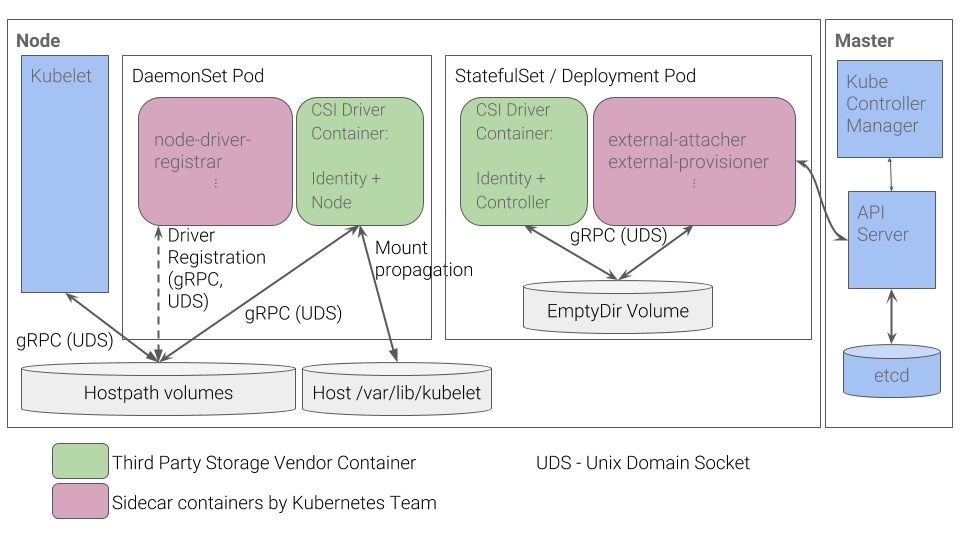
通过实现对上述StatefulSet/Deployment工作负载类型应用(CSI Driver+Identity Controller以及external-attacher+external-provisioner)的高可用即可
母机宕机下的应用高可用
这里我们将Kubernetes集群上的应用分类为:Stateless Application(无状态应用)以及Stateful Application(有状态应用),下面分别介绍这两种类别应用的高可用方案
Stateful Application
对于无状态的服务(通常部署为deployment工作负载),我们可以直接通过设置反亲和+多副本来实现高可用,例如nginx服务:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
app: web-store
replicas: 3
template:
metadata:
labels:
app: web-store
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- web-store
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.16-alpine
如果其中一个pod所在母机宕机了,则在endpoint controller踢掉该pod backend后,服务访问正常
这类服务通常依赖于其它有状态服务,例如:WebServer,APIServer等
Stateful Application
对于有状态的服务,可以按照高可用的实现类型分类如下:
- RWX Type
对于本身基于多副本实现高可用的应用来说,我们可以直接利用反亲和+多副本进行部署(一般部署为deployment类型),后接同一个存储(支持ReadWriteMany,例如:CephFS or Ceph RGW),实现类似无状态服务的高可用模式
其中,docker distribution,helm chartmuseum以及harbor jobservice等都属于这种类型
- Special Type
对于特殊类型的应用,例如database,它们一般有自己定制的高可用方案,例如常用的主从模式
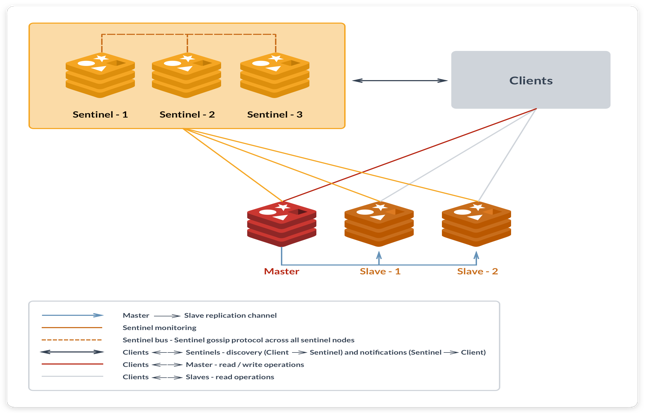
这类应用通常以statefulset的形式进行部署,每个副本对接一个pv,在母机宕机的情况下,由应用本身实现高可用(例如:master选举-主备切换)
其中,redis,postgres,以及各类db都基本是这种模式,如下是redis一主两从三哨兵的高可用方案:
还有更加复杂的高可用方案,例如etcd的Raft一致性算法:
- Distributed Lock Type
Kubernetes Controller就是利用分布式锁实现的高可用
这里归纳了一些应用常用的实现高可用的方案。当然了,各个应用可以定制适合自身的高可用方案,不可能完全一样
母机宕机下的Pod驱逐
母机宕机下的Pod驱逐 - 应用相关
pod驱逐可以使服务自动恢复副本数量。node controller会在节点心跳超时之后一段时间(默认5mins)驱逐该节点上的pod,这个时间由如下参数决定:
- (kube-apiserver)default-not-ready-toleration-seconds:default 300
- (kube-apiserver)default-unreachable-toleration-seconds:default 300

这里面有比较特殊的情况,例如:statefulset,daemonset以及static pod。我们逐一说明:
- statefulset为了保障at most one semantics,需要满足对于指定identity同时只有一个pod存在。在node shutdown后,虽然pod被驱逐了(“Terminating”),但是由于controller无法判断这个statefulset pod是否还在运行(因为并没有彻底删除),故不会产生替换容器,一定是要等到这个pod被完全删除干净(by kubelet),才会产生替换容器(deployment不需要满足这个条件,所以在驱逐pod时,controller会马上产生替换pod,而不需要等待kubelet删除pod)
- 默认情况下daemonset pod会被设置多个tolerations,使其可以容忍节点几乎所有异常的状态,所以不会出现驱逐的情况
- static pod类型类似daemonset会设置tolerations容忍节点异常状态
母机宕机下的Pod驱逐 - 存储相关
当pod使用的volume只支持RWO读写模式时,如果pod所在母机宕机了,并且随后在其它母机上产生了替换副本,则该替换副本的创建会阻塞,如下所示:
$ kubectl get pods -o wide
nginx-7b4d5d9fd-bmc8g 0/1 ContainerCreating 0 0s <none> 10.0.0.1 <none> <none>
nginx-7b4d5d9fd-nqgfz 1/1 Terminating 0 19m 192.28.1.165 10.0.0.2 <none> <none>
$ kubectl describe pods/nginx-7b4d5d9fd-bmc8g
[...truncate...]
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 3m5s default-scheduler Successfully assigned default/nginx-7b4d5d9fd-bmc8g to 10.0.0.1
Warning FailedAttachVolume 3m5s attachdetach-controller Multi-Attach error for volume "pvc-7f68c087-9e56-11ea-a2ef-5254002f7cc9" Volume is already used by pod(s) nginx-7b4d5d9fd-nqgfz
Warning FailedMount 62s kubelet, 10.0.0.1 Unable to mount volumes for pod "nginx-7b4d5d9fd-bmc8g_default(bb5501ca-9fea-11ea-9730-5254002f7cc9)": timeout expired waiting for volumes to attach or mount for pod "default"/"nginx-7b4d5d9fd-nqgfz". list of unmounted volumes=[nginx-data]. list of unattached volumes=[root-certificate default-token-q2vft nginx-data]
这是因为只支持RWO(ReadWriteOnce – the volume can be mounted as read-write by a single node)的volume正常情况下在Kubernetes集群中只能被一个母机attach,由于宕机母机无法执行volume detach操作,其它母机上的pod如果使用相同的volume会被挂住,最终导致容器创建一直阻塞并报错:
Multi-Attach error for volume "pvc-7f68c087-9e56-11ea-a2ef-5254002f7cc9" Volume is already used by pod(s) nginx-7b4d5d9fd-nqgfz
解决办法是采用支持RWX(ReadWriteMany – the volume can be mounted as read-write by many nodes)读写模式的volume。另外如果必须采用只支持RWO模式的volume,则可以执行如下命令强制删除pod,如下:
$ kubectl delete pods/nginx-7b4d5d9fd-nqgfz --force --grace-period=0
之后,对于新创建的pod,attachDetachController会在6mins(代码写死)后强制detach volume,并正常attach,如下:
W0811 04:01:25.024422 1 reconciler.go:328] Multi-Attach error for volume "pvc-e97c6ce6-d8a6-11ea-b832-7a866c097df1" (UniqueName: "kubernetes.io/rbd/k8s:kubernetes-dynamic-pvc-f35fc6fa-d8a6-11ea-bd98-aeb6842de1e3") from node "10.0.0.3" Volume is already exclusively attached to node 10.0.0.2 and can't be attached to another
I0811 04:01:25.024480 1 event.go:209] Event(v1.ObjectReference{Kind:"Pod", Namespace:"default", Name:"default-nginx-6584f7ddb7-jx9s2", UID:"5322240f-db87-11ea-b832-7a866c097df1", APIVersion:"v1", ResourceVersion:"28275287", FieldPath:""}): type: 'Warning' reason: 'FailedAttachVolume' Multi-Attach error for volume "pvc-e97c6ce6-d8a6-11ea-b832-7a866c097df1" Volume is already exclusively attached to one node and can't be attached to another
W0811 04:07:25.047767 1 reconciler.go:232] attacherDetacher.DetachVolume started for volume "pvc-e97c6ce6-d8a6-11ea-b832-7a866c097df1" (UniqueName: "kubernetes.io/rbd/k8s:kubernetes-dynamic-pvc-f35fc6fa-d8a6-11ea-bd98-aeb6842de1e3") on node "10.0.0.2" This volume is not safe to detach, but maxWaitForUnmountDuration 6m0s expired, force detaching
I0811 04:07:25.047860 1 operation_generator.go:500] DetachVolume.Detach succeeded for volume "pvc-e97c6ce6-d8a6-11ea-b832-7a866c097df1" (UniqueName: "kubernetes.io/rbd/k8s:kubernetes-dynamic-pvc-f35fc6fa-d8a6-11ea-bd98-aeb6842de1e3") on node "10.0.0.2"
I0811 04:07:25.148094 1 reconciler.go:288] attacherDetacher.AttachVolume started for volume "pvc-e97c6ce6-d8a6-11ea-b832-7a866c097df1" (UniqueName: "kubernetes.io/rbd/k8s:kubernetes-dynamic-pvc-f35fc6fa-d8a6-11ea-bd98-aeb6842de1e3") from node "10.0.0.3"
I0811 04:07:25.148180 1 operation_generator.go:377] AttachVolume.Attach succeeded for volume "pvc-e97c6ce6-d8a6-11ea-b832-7a866c097df1" (UniqueName: "kubernetes.io/rbd/k8s:kubernetes-dynamic-pvc-f35fc6fa-d8a6-11ea-bd98-aeb6842de1e3") from node "10.0.0.3"
I0811 04:07:25.148266 1 event.go:209] Event(v1.ObjectReference{Kind:"Pod", Namespace:"default", Name:"default-nginx-6584f7ddb7-jx9s2", UID:"5322240f-db87-11ea-b832-7a866c097df1", APIVersion:"v1", ResourceVersion:"28275287", FieldPath:""}): type: 'Normal' reason: 'SuccessfulAttachVolume' AttachVolume.Attach succeeded for volume "pvc-e97c6ce6-d8a6-11ea-b832-7a866c097df1"
而默认的6mins对于生产环境来说太长了,而且Kubernetes并没有提供参数进行配置,因此我向官方提了一个PR用于解决这个问题,如下:
--attach-detach-reconcile-max-wait-unmount-duration duration maximum amount of time the attach detach controller will wait for a volume to be safely unmounted from its node. Once this time has expired, the controller will assume the node or kubelet are unresponsive and will detach the volume anyway. (default 6m0s)
通过配置attach-detach-reconcile-max-wait-unmount-duration,可以缩短替换pod成功运行的时间
另外,注意force detaching逻辑只会在pod被force delete的时候触发,正常delete不会触发该逻辑
高可用总结
实际生产环境需要综合上述因素全面考虑,将整体服务的恢复时间控制在一个可以接受的范围内
Kubernetes备份还原实战
高可用可以在一定程度上实现容灾,但是即便实现集群的高可用,我们依旧会需要备份还原功能,主要原因如下:
- 误删除:运维人员不小心删除了某个namespace或者pv
- 服务器死机:因为物理原因服务器损坏,或者需要重装系统
- 集群迁移:需要将一个集群的数据迁移到另一个集群,用于测试或者其它目的
而对于Kubernetes的备份和还原,社区有一个16年创建的issue,从这个issue中我们可以看出Kubernetes官方并不打算提供Kubernetes备份还原方案以及工具,主要原因有两点:
- 官方认为Kubernetes只提供平台,管理和运行应用(类似于操作系统)。不负责应用层面的备份还原
- 基于Kubernetes集群的应用各不相同,无法(or 不太好)抽象统一备份方案
因此我们必须自己实现该特性。首先我们先梳理一下集群需要备份的东西,如下:
- 应用版本信息(Application Version)
- 应用对应的工作负载,例如:deploymenet,statefulset以及daemonset等等
- 应用需要使用的配置,例如:configmap,secret等等
- 应用状态信息(Application State)
- 应用可以分为有状态应用和无状态应用
- 有状态应用需要备份状态数据,例如:database
备份方案
在理清楚了需要备份的东西后,接下来我将依次介绍Kubernetes集群备份还原的三种方案:
基于etcd的备份还原方案
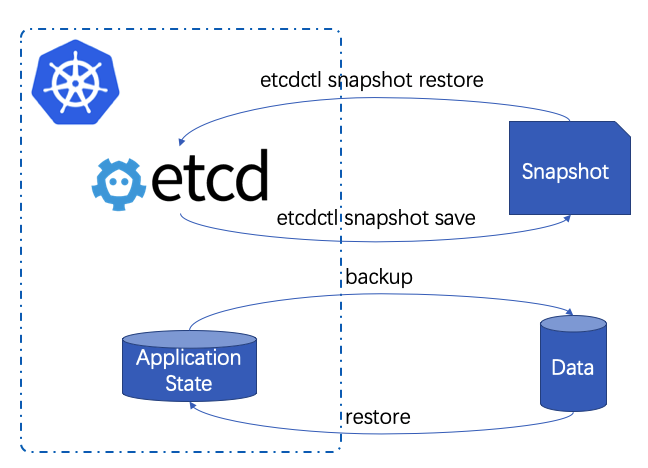
方案要点如下:
- 应用版本备份:Kubernetes集群的所有应用版本信息都存放于etcd中,我们可以直接备份etcd来达到备份版本的目的
- 应用状态备份:可以从应用层或者文件系统层备份应用状态,例如MariaDB采用mysqldump,MongoDB采用mongodump等
优缺点如下:
- Pros
- 原理简单直观
- etcd备份还原支持完善
- Cons
- 备份etcd,包含集群属性。不支持跨集群还原
- etcd包含整个K8s集群元数据,潜在问题多(备份的数据越多,不确定性越大)
基于Velero的备份还原方案(aka Heptio Ark)
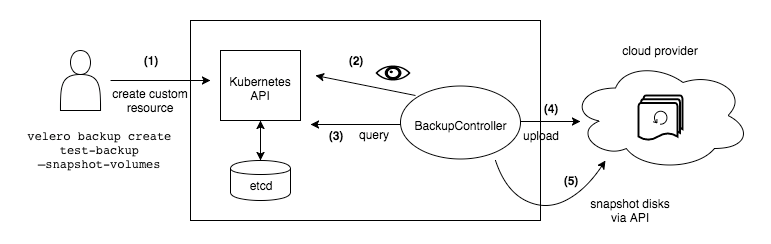
本方案采用社区最流行的云原生备份还原工具Velero。用户通过velero客户端创建备份还原任务,velero controller会监听对应的CRDs,并执行相应的备份和还原操作,将pod以及volume的数据上传到storage provider中,或者从storage provider下载
方案要点如下:
- 应用版本备份:直接备份Kubernetes工作负载以及配置(剔除节点等相关信息,还原时重新创建)
- 应用状态备份:使用volume快照功能或者基于restic实现文件系统级别的备份和还原
这种方案优缺点如下:
- Pros
- 云原生
- 跨集群备份还原
- 支持定期&可选范围备份
- 支持volumesnapshotter plugin&velero restic integration两种方式,支持几乎所有云原生场景。完善的插件机制
- 基于restic支持增量备份
- 兼容K8s CSI快照功能(under development)
- Cons
- Velero restic大文件增量扫描时间长
- Velero restic不支持高可用
- Velero restic备份并发度&效率低
- Velero restore前需要先手动清除相应资源
- 无法支持跨集群版本升级
- 运维成本高
- 不够灵活
对于Velero restic integration,由于v1.5版本之前不支持批量备份Pod,必须手动给所有Pod设置annotation,于是我给官方提交了一个PR用于解决这个问题:
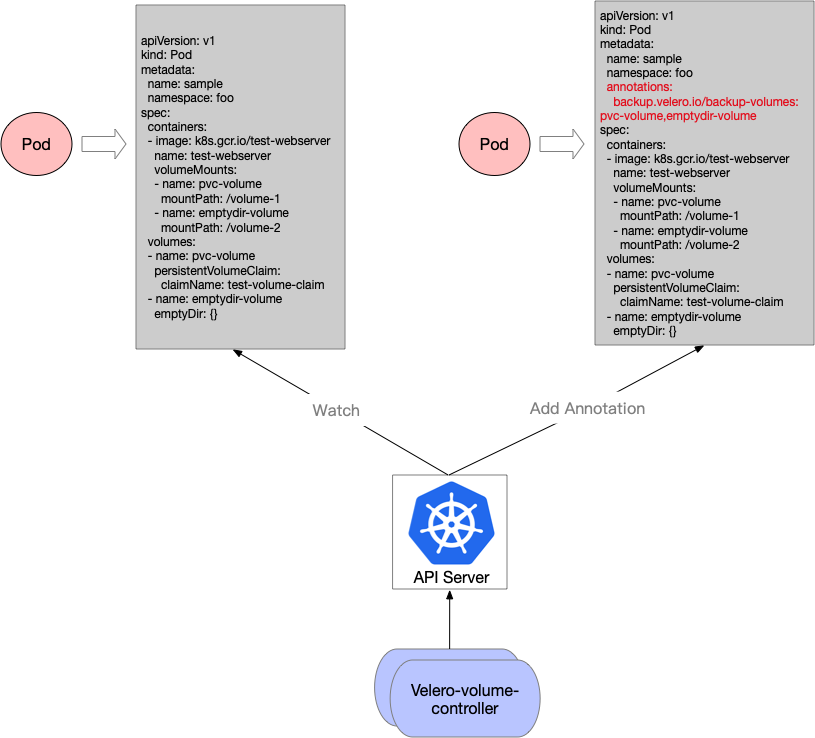
虽然v1.5版本之后支持了Opt-out approach做全量pod volume的备份操作,但是velero-volume-controller支持的细粒度范围控制我认为在短时间内依旧有用
基于应用层的备份还原方案
虽然Velero具备完善且强大的云原生备份还原功能,但是在某些场景下依然表现不够,比如:
- 跨集群备份还原升级,从一个低版本集群备份的数据需要还原到一个更高版本的集群中
- velero都是对整个volume进行备份,某些情况下只需要对volume的部分数据备份
- 需要额外提供storage provider,加上自身组件和架构的复杂性,运维成本比较高
因此,这里设计了第三种备份还原方案 - 基于应用层的备份还原方案:
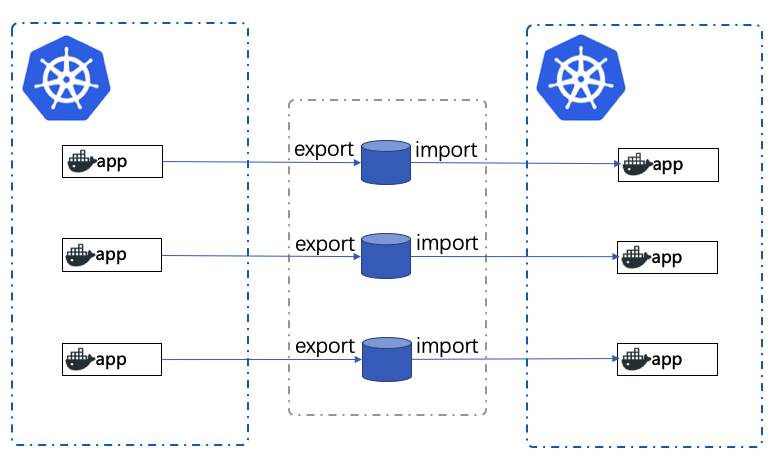
该方案要点如下:
- 应用版本备份:通过版本控制(eg: git)完成集群应用版本的备份
- 应用状态备份:通过应用的导出和导入接口完成集群应用最小数据集的备份和还原
在这种方案中,要求各应用如需备份,则要满足如下规范:应用需要提供导入导出接口,且接口需要在版本管理上实现向后兼容(Backwards compatibility),也即:后续版本应该是可以兼容前面版本的,使用前一个版本的导出数据可以导入到下一个版本的集群中
该方案的设计参考了如下准则:
- 将困难留给自己,将方便留给使用者(Golang&K8s声明式API)
- 专业的事交给专业的人负责
- 备份的数据越小,不确定性越小,成功率越高
优缺点如下:
- Pros
- 备份最小数据集
- 支持跨集群版本升级
- 轻量,足够简单且无需storage providers
- 接口规范,运维成本低
- 灵活度高
- Cons
- 定制备份还原接口,开发成本高
- 仅适用于管理集群
- 几乎全量备份
实战总结
我们按照集群的作用可以将集群分类如下:
- 管理集群:负责管理客户集群,主要部署自研的管理组件
- 特点:组件可能经常升级,内部可以管控部署组件;应用数据量小
- 业务集群:客户实际部署应用的集群
- 特点:无法管控客户部署的应用;应用数据量大
针对这两种集群类型,对备份还原方案选型建议如下:
- 管理集群:由于数据量小且组件可管控,建议优先选择基于应用层的备份还原方案
- 客户集群:由于无法管控集群上部署的应用且数据量可能比较大。建议选择基于Velero的备份还原方案
结束语
对于Kubernetes高可用,本次分享先介绍了Kubernetes集群高可用的整体架构,之后基于该架构从网络,存储,以及应用层面分析了当节点宕机时可能会出现的问题以及对应的思考和解决方案,希望对Kubernetes高可用实践有所助益;另外,介绍了三种Kubernetes备份还原方案,其中基于应用层的备份还原方案和基于Velero的备份还原方案分别适用于管理集群和客户集群。
最后,希望本次的分享对大家有所帮助,也希望未来多多交流。