Contents
Overview
镜像P2P主要用于解决大规模容器分发场景下的镜像拉取性能问题,目前主流的开源解决方案有Dragonfly(Alibaba)以及Kraken(Uber), 这两种解决方案各有优缺点,设计模式也各有不同:
- Dragonfly:采用supernode中心控制设计模式,所有的peer数据传输任务都由supernode负责调度,整个集群将管理集中在supernode组件
- Kraken:采用随机分散设计模式,Tracker组件只负责管理所有peer的连接信息(包括各个peer拥有的数据),而实际的数据传输流程则交由各个peer自行协商决定
Eagle充分参考了Dragonfly,Kraken以及FID的原理和特性。 在上述项目基础上去掉了一些不必要特性,保留了最核心的组件和功能,精简而实用
特性支持
目前Eagle支持如下特性:
- Non-invasive:
Eagle对docker以及docker distribution代码无侵入,可以无感知对接 - High-availability:
Eagle从客户端侧以及服务端侧实现了Tracker以及Seeder的高可用,整个架构无单点故障 - SSI(Seeder Storage Interface):
Eagle对Seeder存储实现了插件式接口,用户可以根据SSI接口实现对接第三方存储(目前默认本地文件系统) - Host level speed limit:
Eagle提供针对整个节点P2P下载和上传的网络限速功能 - LRUCache delete policy:
Eagle提供LRU算法实现Proxy测和Seeder测的磁盘回收功能,并提供参数限制Cache使用大小 - Lightweight:
Eagle由少数核心组件构成,理论上是P2P系统组件的最小集合,属于轻量级的解决方案
未来Eagle希望支持如下特性:
- Peer optimal arithmetic:
Eagle希望实现基于网络拓扑的Peer优选算法,提高传输效率以及节省跨IDC带宽 - Push notification mechanism:实现镜像上传同步更新到
SeederCache,这样可以最大限度减少Seeder回源操作
其中,Peer optimal arithmetic是目前所有开源项目都没有实现的特性(参考Kraken #244和Dragonfly #1311),也是本项目的重点研究对象
原理
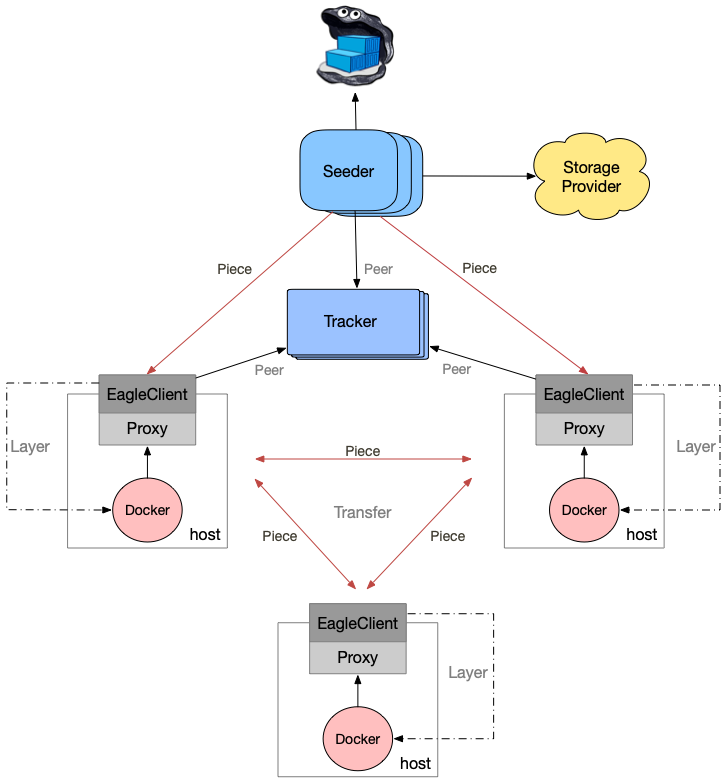
Eagle由如下组件组成:
- Proxy:部署在各个节点上,充当docker的代理,对docker拉取镜像的请求进行过滤以及将请求转发给P2P网络(EagleClient)
- EagleClient:P2P网络中的Peer端,负责执行P2P下载以及上传具体任务
- Seeder:种子服务器,负责生成镜像分层的种子文件,并充当P2P网络镜像分层数据文件的第一个上传Peer
- Tracker:保存了P2P网络拓扑中每个Peer的地址信息,同时记录了每个Peer的数据下载情况
- Origin:镜像仓库,可以是任何镜像仓库(docker distribution, harbor, quay等)的入口地址
整个架构图如下:
Workflow
当docker执行拉取镜像操作时,其请求会被Proxy劫持。Proxy会对请求进行过滤,如果是对镜像分层的拉取请求,则会转交给EagleClient执行;否则直接代理请求
EagleClient在接受到Proxy转发过来的请求后,首先判断本地磁盘是否存在对应的文件,如果存在则直接返回;否则进入P2P下载流程
整个P2P下载流程大致如下:
EagleClient首先会从Seeder获取镜像分层的种子文件。Seeder在接受到请求后,检查本地是否存在对应文件,如果不存在,则会回源拉取,然后根据数据文件生成种子文件,返回给EagleClient;并向Tracker宣布自己作为该镜像分层的uploader。EagleClient获取到种子文件后,会向Tracker获取P2P网络中该数据文件对应分片的Peer地址和下载信息,然后依据BT协议进行P2P下载
请求流程图如下:

实现
Eagle的代码短小而精炼,接下来我们从代码层面探讨一下上述特性的具体实现
GRPC
EagleClient使用GRPC协议从Seeder获取种子文件,以提高传输效率
协议文件metainfo.proto内容如下:
syntax = "proto3";
package metainfo;
// The metainfo service definition.
service MetaInfo {
// Get metainfo
rpc GetMetaInfo (MetaInfoRequest) returns (MetaInfoReply) {}
}
// The request message containing the source request
message MetaInfoRequest {
string url = 1;
}
// The response message containing the metainfo bytes
message MetaInfoReply {
bytes metainfo = 1;
}
EagleClient newMetaInfoClient:
func (e *BtEngine) newMetaInfoClient() (pb.MetaInfoClient, error) {
rsv, err := endpoint.NewResolverGroup("eagleclient")
if err != nil {
return nil, err
}
rsv.SetEndpoints(e.seeders)
name := fmt.Sprintf("eagleclient-%s", picker.RoundrobinBalanced.String())
balancer.RegisterBuilder(balancer.Config{
Policy: picker.RoundrobinBalanced,
Name: name,
Logger: zap.NewExample(),
})
conn, err := grpc.Dial(fmt.Sprintf("endpoint://eagleclient/"), grpc.WithInsecure(), grpc.WithBalancerName(name))
if err != nil {
return nil, fmt.Errorf("failed to dial seeder: %s", err)
}
return pb.NewMetaInfoClient(conn), nil
}
Seeder GetMetaInfo:
// GetMetaData get torrent of layer
func (s *Seeder) GetMetaInfo(ctx context.Context, metaInfoReq *pb.MetaInfoRequest) (*pb.MetaInfoReply, error) {
log.Debugf("Access: %s", metaInfoReq.Url)
digest := metaInfoReq.Url[strings.LastIndex(metaInfoReq.Url, "/")+1:]
id := distdigests.Digest(digest).Encoded()
log.Debugf("Start to get metadata of layer %s", id)
err := s.getMetaDataSync(metaInfoReq.Url, id)
if err != nil {
return nil, fmt.Errorf("Get metainfo from origin failed: %v", err)
}
torrentFile := s.storage.GetTorrentFilePath(id)
content, err := s.storage.Download(torrentFile)
if err != nil {
return nil, fmt.Errorf("Download metainfo file failed: %v", err)
}
return &pb.MetaInfoReply{Metainfo: content}, nil
}
Seeder Storage Interface(SSI)
为了使Seeder存储接入更加友善,Eagle提供了SSI以便用户进行定制化开发需求。Eagle默认提供了本地文件系统的插件实现,参考这部分代码,用户可以很容易地实现自己的第三方存储接口
目录结构如下:
$ tree lib
lib
└── backend
├── fsbackend
│ ├── config.go
│ ├── fs.go
│ └── storage.go
└── storage.go
SSI如下:
// Storage defines an interface for accessing blobs on a remote storage backend.
//
// Implementations of Storage must be thread-safe, since they are cached and
// used concurrently by Manager.
type Storage interface {
// Create creates torrent with meta info
CreateWithMetaInfo(name string, info *metainfo.MetaInfo) error
// Stat is useful when we need to quickly know if a blob exists (and maybe
// some basic information about it), without downloading the entire blob,
// which may be very large.
Stat(name string) (*FileInfo, error)
// Upload uploads data into name.
Upload(name string, data []byte) error
// Download downloads name into dst. All implementations should return
// backenderrors.ErrBlobNotFound when the blob was not found.
Download(name string) ([]byte, error)
// Delete removes relevant name
Delete(name string) error
// List lists entries whose names start with prefix.
List(prefix string) ([]*FileInfo, error)
// GetFilePath returns data path
GetFilePath(id string) string
// GetTorrentFilePath returns torrent path
GetTorrentFilePath(id string) string
// GetDataDir returns directory of data
GetDataDir() string
// GetTorrentDir returns directory of torrent
GetTorrentDir() string
}
LRUCache
为了实现Cache的定期清理,Eagle实现了thread-safe LRUCache算法,该算法会删除最久未使用的镜像分层文件,以腾出Cache空间,同时增加Cache命中率;另外该算法实现了在Cache不命中的情况下,只从远端获取一次数据的并发控制逻辑:
// EvictCallback is used to get a callback when a cache entry is evicted
type EvictCallback func(string)
type LruCache struct {
sync.RWMutex
limitSize int64
currentSize int64
evictList *list.List
items map[string]*list.Element
onEvict EvictCallback
}
// Entry is used to hold a value in the evictList
type entry struct {
key string
value Entry
}
type Entry struct {
Done chan struct{}
Completed bool
Size int64
}
具体请参考:pkg/utils/lrucache/lrucache.go
Code Structure
为了使Eagle项目结构看起来尽可能清晰,Eagle各组件均采用了相同的代码结构,如下:
$ tree seeder
seeder
├── bt
│ └── seeder.go
├── cmd
│ ├── cmd.go
│ └── config.go
└── main.go
$ tree proxy
proxy
├── cmd
│ ├── cmd.go
│ └── config.go
├── main.go
├── routes
│ ├── process.go
│ └── route.go
└── transport
└── transport.go
main.go为入口:
package main
import "github.com/duyanghao/eagle/proxy/cmd"
func main() {
cmd.Run(cmd.ParseFlags())
}
执行cmd.Run逻辑:
func Run(flags *Flags) {
// create config
log.Infof("Start to load config %s ...", flags.ConfigFile)
config, err := LoadConfig(flags.ConfigFile)
if err != nil {
log.Fatalf("Failed to load config: %v", err)
}
log.Infof("Load config %s successfully", flags.ConfigFile)
// set log level
if config.ProxyCfg.Verbose {
log.SetLevel(log.DebugLevel)
} else {
log.SetLevel(log.InfoLevel)
}
// start eagleClient
log.Infof("Start eagleClient ...")
c := &eagleclient.Config{
EnableUpload: true,
EnableSeeding: true,
IncomingPort: config.ClientCfg.Port,
DownloadTimeout: time.Duration(config.ClientCfg.DownloadTimeout),
UploadRateLimit: ratelimiter.RateConvert(config.ClientCfg.UploadRateLimit),
DownloadRateLimit: ratelimiter.RateConvert(config.ClientCfg.DownloadRateLimit),
CacheLimitSize: ratelimiter.RateConvert(config.ClientCfg.LimitSize),
}
eagleClient := eagleclient.NewBtEngine(config.ClientCfg.RootDirectory, config.ClientCfg.Trackers, config.ClientCfg.Seeders, c)
proxyRoundTripper := transport.NewProxyRoundTripper(eagleClient, config.ProxyCfg.Rules)
err = proxyRoundTripper.P2PClient.Run()
if err != nil {
log.Fatal("Start eagleClient failure: %v", err)
}
log.Infof("Start eagleClient successfully ...")
// init routes
routes.InitMux()
// start proxy
log.Infof("Launch proxy on port: %d", config.ProxyCfg.Port)
if config.ProxyCfg.CertFile != "" && config.ProxyCfg.KeyFile != "" {
err = http.ListenAndServeTLS(fmt.Sprintf(":%d", config.ProxyCfg.Port), config.ProxyCfg.CertFile, config.ProxyCfg.KeyFile, nil)
} else {
err = http.ListenAndServe(fmt.Sprintf(":%d", config.ProxyCfg.Port), nil)
}
if err != nil {
log.Fatal(err)
}
}
High Availability
1. client-side
目前Eagle从代码层面实现了基于client-side端的高可用设计
- Seeder
Eagle参考etcd clientv3-grpc1.23 Balancer实现了Seeder的高可用轮询方案:
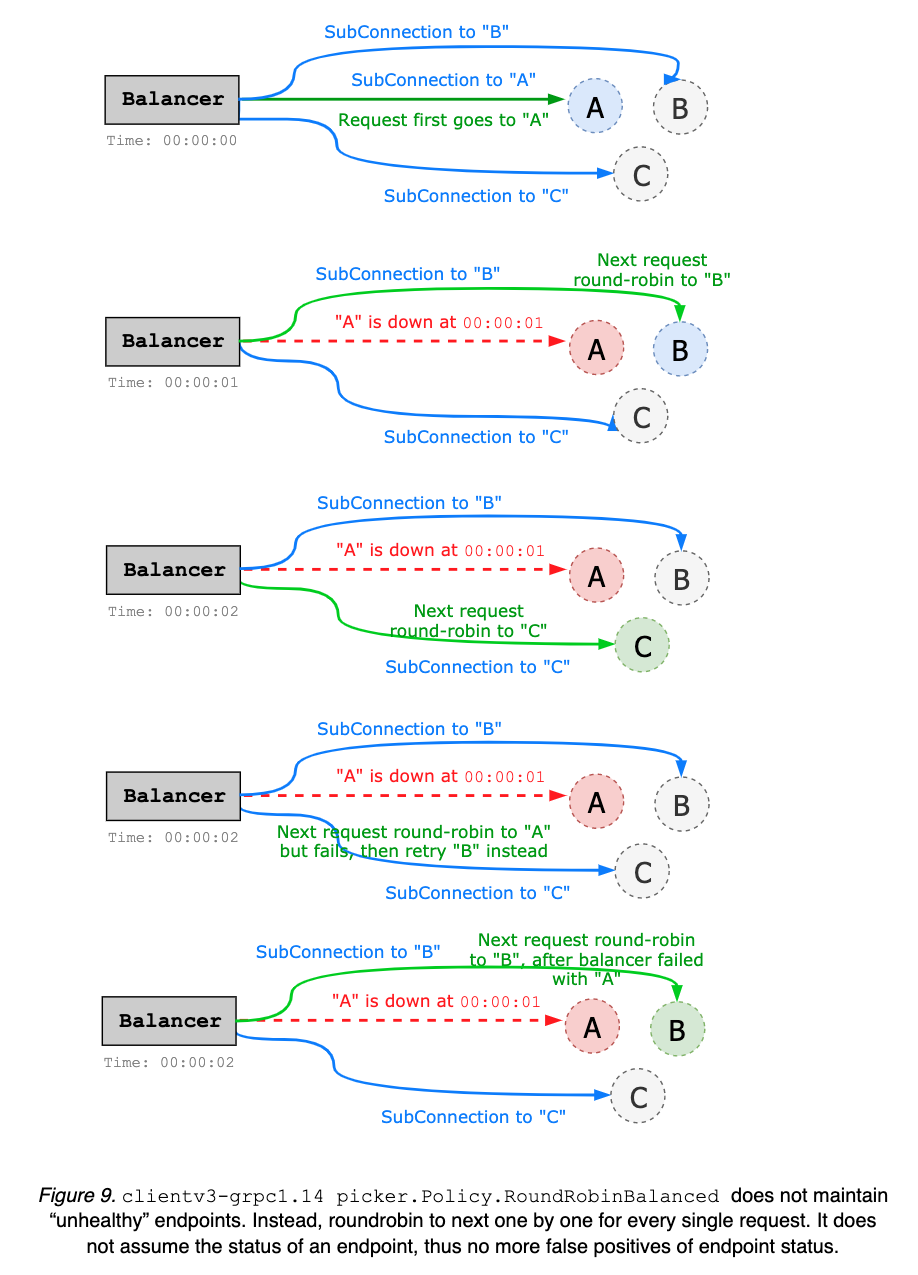
具体代码参考:EagleClient balancer
- Tracker
目前Tracker端的高可用方案采用的是BT协议中的announce-list字段。简单来说,就是BT client会向每个Tracker发出announce间隔请求,之后BT下载过程中会选择其中一个Tracker获取Peer列表信息和数据下载状态,进行下载操作,如果其中某一个Tracker挂掉了,则可以向其它Tracker发出相同请求,从而实现高可用
2. server-side
用户可以从架构层面来实现server-side端的高可用方案,最通用和简单的设计就是采用VIP的方案。Eagle对接VIP,而VIP后面对接Seeder和Tracker,从而实现高可用。Seeder高可用架构图如下:
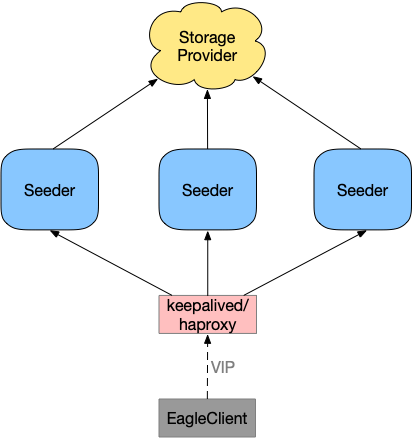
Tracker依此类推
Comparison
目前社区最流行的P2P解决方案当属Dragonfly,Dragonfly提供了许多生产环境需要使用的功能,比如:断点续传,母机限速以及跨IDC解决方案等。但是Dragonfly最大的问题就是它的supernode中心设计。在这种设计中,supernode需要管理整个P2P网络中的所有节点数据传输,虽然理论上可以实现全局的最佳分配算法,但是却很难落地实现。所以实际使用中,随着镜像分层大小增加以及集群规模扩大,整个Dragonfly系统会线性变慢。另外Dragonfly不支持supernode节点的高可用部署,这也是致命的一个缺点
Kraken在设计理论上区分于Dragonfly,采用了分散式设计。Tracker只负责管理各节点的连接信息,不负责具体的数据传输分配协商,理论上可以更好地支持集群规模的快速增长。另外Kraken在BT协议基础上定制了传输协议,以更大程度提高传输效率
Eagle在设计上采用了Kraken的随机分散式模式,并去掉了Kraken一些非核心组件;在功能支持上保留了Kraken和Dragonfly的优秀特性(例如:SSI以及Host level speed limit)。因此,相比Dragonfly和Kraken,Eagle原理更加简单,特性支持虽然有限,但轻便,精简且实用
Suggestion
最后,对于如何选择P2P开源解决方案,我的建议是:Dragonfly和Kraken功能都足够强大,且在企业生产环境中均有落地,但是相应的运维成本也较大,所以如果是大型企业用户或者是付费用户则可以选择;但如果你想选择一个维护成本更小,更加轻量级的解决方案,那么Eagle就是首选